第十章:批处理
带有太强个人色彩的系统无法成功。当最初的设计完成并且相对稳定时,不同的人们以自己的方式进行测试,真正的考验才开始。
—— 高德纳
在本书的前两部分中,我们讨论了很多关于 请求 和 查询 以及相应的 响应 或 结果。许多现有数据系统中都采用这种数据处理方式:你发送请求指令,一段时间后(我们期望)系统会给出一个结果。数据库、缓存、搜索索引、Web 服务器以及其他一些系统都以这种方式工作。
像这样的 在线(online) 系统,无论是浏览器请求页面还是调用远程 API 的服务,我们通常认为请求是由人类用户触发的,并且正在等待响应。他们不应该等太久,所以我们非常关注系统的响应时间(请参阅 “描述性能”)。
Web 和越来越多的基于 HTTP/REST 的 API 使交互的请求 / 响应风格变得如此普遍,以至于很容易将其视为理所当然。但我们应该记住,这不是构建系统的唯一方式,其他方法也有其优点。我们来看看三种不同类型的系统:
服务(在线系统)
服务等待客户的请求或指令到达。每收到一个,服务会试图尽快处理它,并发回一个响应。响应时间通常是服务性能的主要衡量指标,可用性通常非常重要(如果客户端无法访问服务,用户可能会收到错误消息)。
批处理系统(离线系统)
一个批处理系统有大量的输入数据,跑一个 作业(job) 来处理它,并生成一些输出数据,这往往需要一段时间(从几分钟到几天),所以通常不会有用户等待作业完成。相反,批量作业通常会定期运行(例如,每天一次)。批处理作业的主要性能衡量标准通常是吞吐量(处理特定大小的输入所需的时间)。本章中讨论的就是批处理。
流处理系统(准实时系统)
流处理介于在线和离线(批处理)之间,所以有时候被称为 准实时(near-real-time) 或 准在线(nearline) 处理。像批处理系统一样,流处理消费输入并产生输出(并不需要响应请求)。但是,流式作业在事件发生后不久就会对事件进行操作,而批处理作业则需等待固定的一组输入数据。这种差异使流处理系统比起批处理系统具有更低的延迟。由于流处理基于批处理,我们将在 第十一章 讨论它。
正如我们将在本章中看到的那样,批处理是构建可靠、可伸缩和可维护应用程序的重要组成部分。例如,2004 年发布的批处理算法 Map-Reduce(可能被过分热情地)被称为 “造就 Google 大规模可伸缩性的算法”【2】。随后在各种开源数据系统中得到应用,包括 Hadoop、CouchDB 和 MongoDB。
与多年前为数据仓库开发的并行处理系统【3,4】相比,MapReduce 是一个相当低级别的编程模型,但它使得在商用硬件上能进行的处理规模迈上一个新的台阶。虽然 MapReduce 的重要性正在下降【5】,但它仍然值得去理解,因为它描绘了一幅关于批处理为什么有用,以及如何做到有用的清晰图景。
实际上,批处理是一种非常古老的计算方式。早在可编程数字计算机诞生之前,打孔卡制表机(例如 1890 年美国人口普查【6】中使用的霍尔里斯机)实现了半机械化的批处理形式,从大量输入中汇总计算。 Map-Reduce 与 1940 年代和 1950 年代广泛用于商业数据处理的机电 IBM 卡片分类机器有着惊人的相似之处【7】。正如我们所说,历史总是在不断重复自己。
在本章中,我们将了解 MapReduce 和其他一些批处理算法和框架,并探索它们在现代数据系统中的作用。但首先我们将看看使用标准 Unix 工具的数据处理。即使你已经熟悉了它们,Unix 的哲学也值得一读,Unix 的思想和经验教训可以迁移到大规模、异构的分布式数据系统中。
使用Unix工具的批处理
我们从一个简单的例子开始。假设你有一台 Web 服务器,每次处理请求时都会在日志文件中附加一行。例如,使用 nginx 默认的访问日志格式,日志的一行可能如下所示:
1 | 216.58.210.78 - - [27/Feb/2015:17:55:11 +0000] "GET /css/typography.css HTTP/1.1" |
(实际上这只是一行,分成多行只是为了便于阅读。)这一行中有很多信息。为了解释它,你需要了解日志格式的定义,如下所示:
1 | remote_addr - $remote_user [$time_local] "$request" |
日志的这一行表明在 UTC 时间的 2015 年 2 月 27 日 17 点 55 分 11 秒,服务器从客户端 IP 地址 216.58.210.78 接收到对文件 /css/typography.css 的请求。用户没有认证,所以 $remote_user 被设置为连字符(-)。响应状态是 200(即请求成功),响应的大小是 3377 字节。网页浏览器是 Chrome 40,它加载了这个文件是因为该文件在网址为 http://martin.kleppmann.com/ 的页面中被引用到了。
简单日志分析
很多工具可以从这些日志文件生成关于网站流量的漂亮的报告,但为了练手,让我们使用基本的 Unix 功能创建自己的工具。 例如,假设你想在你的网站上找到五个最受欢迎的网页。 则可以在 Unix shell 中这样做:[^i]
[^i]: 有些人认为 cat 这里并没有必要,因为输入文件可以直接作为 awk 的参数。 但这种写法让线性管道更为显眼。
1 | cat /var/log/nginx/access.log | #1 |
- 读取日志文件
- 将每一行按空格分割成不同的字段,每行只输出第七个字段,恰好是请求的 URL。在我们的例子中是
/css/typography.css。 - 按字母顺序排列请求的 URL 列表。如果某个 URL 被请求过 n 次,那么排序后,文件将包含连续重复出现 n 次的该 URL。
uniq命令通过检查两个相邻的行是否相同来过滤掉输入中的重复行。-c则表示还要输出一个计数器:对于每个不同的 URL,它会报告输入中出现该 URL 的次数。- 第二种排序按每行起始处的数字(
-n)排序,这是 URL 的请求次数。然后逆序(-r)返回结果,大的数字在前。 - 最后,只输出前五行(
-n 5),并丢弃其余的。该系列命令的输出如下所示:
1 | 4189 /favicon.ico |
如果你不熟悉 Unix 工具,上面的命令行可能看起来有点吃力,但是它非常强大。它能在几秒钟内处理几 GB 的日志文件,并且你可以根据需要轻松修改命令。例如,如果要从报告中省略 CSS 文件,可以将 awk 参数更改为 '$7 !~ /\.css$/ {print $7}', 如果想统计最多的客户端 IP 地址,可以把 awk 参数改为 '{print $1}',等等。
我们不会在这里详细探索 Unix 工具,但是它非常值得学习。令人惊讶的是,使用 awk、sed、grep、sort、uniq 和 xargs 的组合,可以在几分钟内完成许多数据分析,并且它们的性能相当的好【8】。
命令链与自定义程序
除了 Unix 命令链,你还可以写一个简单的程序来做同样的事情。例如在 Ruby 中,它可能看起来像这样:
1 | counts = Hash.new(0) # 1 |
counts是一个存储计数器的哈希表,保存了每个 URL 被浏览的次数,默认为 0。- 逐行读取日志,抽取每行第七个被空格分隔的字段为 URL(这里的数组索引是 6,因为 Ruby 的数组索引从 0 开始计数)
- 将日志当前行中 URL 对应的计数器值加一。
- 按计数器值(降序)对哈希表内容进行排序,并取前五位。
- 打印出前五个条目。
这个程序并不像 Unix 管道那样简洁,但是它的可读性很强,喜欢哪一种属于口味的问题。但两者除了表面上的差异之外,执行流程也有很大差异,如果你在大文件上运行此分析,则会变得明显。
排序 VS 内存中的聚合
Ruby 脚本在内存中保存了一个 URL 的哈希表,将每个 URL 映射到它出现的次数。 Unix 管道没有这样的哈希表,而是依赖于对 URL 列表的排序,在这个 URL 列表中,同一个 URL 的只是简单地重复出现。
哪种方法更好?这取决于你有多少个不同的 URL。对于大多数中小型网站,你可能可以为所有不同网址提供一个计数器(假设我们使用 1GB 内存)。在此例中,作业的 工作集(working set,即作业需要随机访问的内存大小)仅取决于不同 URL 的数量:如果日志中只有单个 URL,重复出现一百万次,则散列表所需的空间表就只有一个 URL 加上一个计数器的大小。当工作集足够小时,内存散列表表现良好,甚至在性能较差的笔记本电脑上也可以正常工作。
另一方面,如果作业的工作集大于可用内存,则排序方法的优点是可以高效地使用磁盘。这与我们在 “SSTables 和 LSM 树” 中讨论过的原理是一样的:数据块可以在内存中排序并作为段文件写入磁盘,然后多个排序好的段可以合并为一个更大的排序文件。 归并排序具有在磁盘上运行良好的顺序访问模式。 (请记住,针对顺序 I/O 进行优化是 第三章 中反复出现的主题,相同的模式在此重现)
GNU Coreutils(Linux)中的 sort 程序通过溢出至磁盘的方式来自动应对大于内存的数据集,并能同时使用多个 CPU 核进行并行排序【9】。这意味着我们之前看到的简单的 Unix 命令链很容易伸缩至大数据集,且不会耗尽内存。瓶颈可能是从磁盘读取输入文件的速度。
Unix哲学
我们可以非常容易地使用前一个例子中的一系列命令来分析日志文件,这并非巧合:事实上,这实际上是 Unix 的关键设计思想之一,而且它直至今天也仍然令人讶异地重要。让我们更深入地研究一下,以便从 Unix 中借鉴一些想法【10】。
Unix 管道的发明者道格・麦克罗伊(Doug McIlroy)在 1964 年首先描述了这种情况【11】:“我们需要一种类似园艺胶管的方式来拼接程序 —— 当我们需要将消息从一个程序传递另一个程序时,直接接上去就行。I/O 应该也按照这种方式进行 “。水管的类比仍然在生效,通过管道连接程序的想法成为了现在被称为 Unix 哲学 的一部分 —— 这一组设计原则在 Unix 用户与开发者之间流行起来,该哲学在 1978 年表述如下【12,13】:
- 让每个程序都做好一件事。要做一件新的工作,写一个新程序,而不是通过添加 “功能” 让老程序复杂化。
- 期待每个程序的输出成为另一个程序的输入。不要将无关信息混入输出。避免使用严格的列数据或二进制输入格式。不要坚持交互式输入。
- 设计和构建软件时,即使是操作系统,也让它们能够尽早地被试用,最好在几周内完成。不要犹豫,扔掉笨拙的部分,重建它们。
- 优先使用工具来减轻编程任务,即使必须曲线救国编写工具,且在用完后很可能要扔掉大部分。
这种方法 —— 自动化,快速原型设计,增量式迭代,对实验友好,将大型项目分解成可管理的块 —— 听起来非常像今天的敏捷开发和 DevOps 运动。奇怪的是,四十年来变化不大。
sort 工具是一个很好的例子。可以说它比大多数编程语言标准库中的实现(它们不会利用磁盘或使用多线程,即使这样做有很大好处)要更好。然而,单独使用 sort 几乎没什么用。它只能与其他 Unix 工具(如 uniq)结合使用。
像 bash 这样的 Unix shell 可以让我们轻松地将这些小程序组合成令人讶异的强大数据处理任务。尽管这些程序中有很多是由不同人群编写的,但它们可以灵活地结合在一起。 Unix 如何实现这种可组合性?
统一的接口
如果你希望一个程序的输出成为另一个程序的输入,那意味着这些程序必须使用相同的数据格式 —— 换句话说,一个兼容的接口。如果你希望能够将任何程序的输出连接到任何程序的输入,那意味着所有程序必须使用相同的 I/O 接口。
在 Unix 中,这种接口是一个 文件(file,更准确地说,是一个文件描述符)。一个文件只是一串有序的字节序列。因为这是一个非常简单的接口,所以可以使用相同的接口来表示许多不同的东西:文件系统上的真实文件,到另一个进程(Unix 套接字,stdin,stdout)的通信通道,设备驱动程序(比如 /dev/audio 或 /dev/lp0),表示 TCP 连接的套接字,等等。很容易将这些设计视为理所当然的,但实际上能让这些差异巨大的东西共享一个统一的接口是非常厉害的,这使得它们可以很容易地连接在一起 [^ii]。
[^ii]: 统一接口的另一个例子是 URL 和 HTTP,这是 Web 的基石。 一个 URL 标识一个网站上的一个特定的东西(资源),你可以链接到任何其他网站的任何网址。 具有网络浏览器的用户因此可以通过跟随链接在网站之间无缝跳转,即使服务器可能由完全不相关的组织维护。 这个原则现在似乎非常明显,但它却是网络取能取得今天成就的关键。 之前的系统并不是那么统一:例如,在公告板系统(BBS)时代,每个系统都有自己的电话号码和波特率配置。 从一个 BBS 到另一个 BBS 的引用必须以电话号码和调制解调器设置的形式;用户将不得不挂断,拨打其他 BBS,然后手动找到他们正在寻找的信息。 直接链接到另一个 BBS 内的一些内容当时是不可能的。
按照惯例,许多(但不是全部)Unix 程序将这个字节序列视为 ASCII 文本。我们的日志分析示例使用了这个事实:awk、sort、uniq 和 head 都将它们的输入文件视为由 \n(换行符,ASCII 0x0A)字符分隔的记录列表。\n 的选择是任意的 —— 可以说,ASCII 记录分隔符 0x1E 本来就是一个更好的选择,因为它是为了这个目的而设计的【14】,但是无论如何,所有这些程序都使用相同的记录分隔符允许它们互操作。
每条记录(即一行输入)的解析则更加模糊。 Unix 工具通常通过空白或制表符将行分割成字段,但也使用 CSV(逗号分隔),管道分隔和其他编码。即使像 xargs 这样一个相当简单的工具也有六个命令行选项,用于指定如何解析输入。
ASCII 文本的统一接口大多数时候都能工作,但它不是很优雅:我们的日志分析示例使用 {print $7} 来提取网址,这样可读性不是很好。在理想的世界中可能是 {print $request_url} 或类似的东西。我们稍后会回顾这个想法。
尽管几十年后还不够完美,但统一的 Unix 接口仍然是非常出色的设计。没有多少软件能像 Unix 工具一样交互组合的这么好:你不能通过自定义分析工具轻松地将电子邮件帐户的内容和在线购物历史记录以管道传送至电子表格中,并将结果发布到社交网络或维基。今天,像 Unix 工具一样流畅地运行程序是一种例外,而不是规范。
即使是具有 相同数据模型 的数据库,将数据从一种数据库导出再导入到另一种数据库也并不容易。缺乏整合导致了数据的 巴尔干化[^译注i]。
[^译注i]: 巴尔干化(Balkanization) 是一个常带有贬义的地缘政治学术语,其定义为:一个国家或政区分裂成多个互相敌对的国家或政区的过程。
逻辑与布线相分离
Unix 工具的另一个特点是使用标准输入(stdin)和标准输出(stdout)。如果你运行一个程序,而不指定任何其他的东西,标准输入来自键盘,标准输出指向屏幕。但是,你也可以从文件输入和 / 或将输出重定向到文件。管道允许你将一个进程的标准输出附加到另一个进程的标准输入(有个小内存缓冲区,而不需要将整个中间数据流写入磁盘)。
如果需要,程序仍然可以直接读取和写入文件,但 Unix 方法在程序不关心特定的文件路径、只使用标准输入和标准输出时效果最好。这允许 shell 用户以任何他们想要的方式连接输入和输出;该程序不知道或不关心输入来自哪里以及输出到哪里。 (人们可以说这是一种 松耦合(loose coupling),晚期绑定(late binding)【15】或 控制反转(inversion of control)【16】)。将输入 / 输出布线与程序逻辑分开,可以将小工具组合成更大的系统。
你甚至可以编写自己的程序,并将它们与操作系统提供的工具组合在一起。你的程序只需要从标准输入读取输入,并将输出写入标准输出,它就可以加入数据处理的管道中。在日志分析示例中,你可以编写一个将 Usage-Agent 字符串转换为更灵敏的浏览器标识符,或者将 IP 地址转换为国家代码的工具,并将其插入管道。sort 程序并不关心它是否与操作系统的另一部分或者你写的程序通信。
但是,使用 stdin 和 stdout 能做的事情是有限的。需要多个输入或输出的程序虽然可能,却非常棘手。你没法将程序的输出管道连接至网络连接中【17,18】[^iii] 。如果程序直接打开文件进行读取和写入,或者将另一个程序作为子进程启动,或者打开网络连接,那么 I/O 的布线就取决于程序本身了。它仍然可以被配置(例如通过命令行选项),但在 Shell 中对输入和输出进行布线的灵活性就少了。
[^iii]: 除了使用一个单独的工具,如 netcat 或 curl。 Unix 起初试图将所有东西都表示为文件,但是 BSD 套接字 API 偏离了这个惯例【17】。研究用操作系统 Plan 9 和 Inferno 在使用文件方面更加一致:它们将 TCP 连接表示为 /net/tcp 中的文件【18】。
透明度和实验
使 Unix 工具如此成功的部分原因是,它们使查看正在发生的事情变得非常容易:
- Unix 命令的输入文件通常被视为不可变的。这意味着你可以随意运行命令,尝试各种命令行选项,而不会损坏输入文件。
- 你可以在任何时候结束管道,将管道输出到
less,然后查看它是否具有预期的形式。这种检查能力对调试非常有用。 - 你可以将一个流水线阶段的输出写入文件,并将该文件用作下一阶段的输入。这使你可以重新启动后面的阶段,而无需重新运行整个管道。
因此,与关系数据库的查询优化器相比,即使 Unix 工具非常简单,但仍然非常有用,特别是对于实验而言。
然而,Unix 工具的最大局限在于它们只能在一台机器上运行 —— 而 Hadoop 这样的工具即应运而生。
MapReduce和分布式文件系统
MapReduce 有点像 Unix 工具,但分布在数千台机器上。像 Unix 工具一样,它相当简单粗暴,但令人惊异地管用。一个 MapReduce 作业可以和一个 Unix 进程相类比:它接受一个或多个输入,并产生一个或多个输出。
和大多数 Unix 工具一样,运行 MapReduce 作业通常不会修改输入,除了生成输出外没有任何副作用。输出文件以连续的方式一次性写入(一旦写入文件,不会修改任何现有的文件部分)。
虽然 Unix 工具使用 stdin 和 stdout 作为输入和输出,但 MapReduce 作业在分布式文件系统上读写文件。在 Hadoop 的 MapReduce 实现中,该文件系统被称为 HDFS(Hadoop 分布式文件系统),一个 Google 文件系统(GFS)的开源实现【19】。
除 HDFS 外,还有各种其他分布式文件系统,如 GlusterFS 和 Quantcast File System(QFS)【20】。诸如 Amazon S3、Azure Blob 存储和 OpenStack Swift【21】等对象存储服务在很多方面都是相似的 [^iv]。在本章中,我们将主要使用 HDFS 作为示例,但是这些原则适用于任何分布式文件系统。
[^iv]: 一个不同之处在于,对于 HDFS,可以将计算任务安排在存储特定文件副本的计算机上运行,而对象存储通常将存储和计算分开。如果网络带宽是一个瓶颈,从本地磁盘读取有性能优势。但是请注意,如果使用纠删码(Erasure Coding),则会丢失局部性,因为来自多台机器的数据必须进行合并以重建原始文件【20】。
与网络连接存储(NAS)和存储区域网络(SAN)架构的共享磁盘方法相比,HDFS 基于 无共享 原则(请参阅 第二部分 的介绍)。共享磁盘存储由集中式存储设备实现,通常使用定制硬件和专用网络基础设施(如光纤通道)。而另一方面,无共享方法不需要特殊的硬件,只需要通过传统数据中心网络连接的计算机。
HDFS 在每台机器上运行了一个守护进程,它对外暴露网络服务,允许其他节点访问存储在该机器上的文件(假设数据中心中的每台通用计算机都挂载着一些磁盘)。名为 NameNode 的中央服务器会跟踪哪个文件块存储在哪台机器上。因此,HDFS 在概念上创建了一个大型文件系统,可以使用所有运行有守护进程的机器的磁盘。
为了容忍机器和磁盘故障,文件块被复制到多台机器上。复制可能意味着多个机器上的相同数据的多个副本,如 第五章 中所述,或者诸如 Reed-Solomon 码这样的纠删码方案,它能以比完全复制更低的存储开销来支持恢复丢失的数据【20,22】。这些技术与 RAID 相似,后者可以在连接到同一台机器的多个磁盘上提供冗余;区别在于在分布式文件系统中,文件访问和复制是在传统的数据中心网络上完成的,没有特殊的硬件。
HDFS 的可伸缩性已经很不错了:在撰写本书时,最大的 HDFS 部署运行在上万台机器上,总存储容量达数百 PB【23】。如此大的规模已经变得可行,因为使用商品硬件和开源软件的 HDFS 上的数据存储和访问成本远低于在专用存储设备上支持同等容量的成本【24】。
MapReduce作业执行
MapReduce 是一个编程框架,你可以使用它编写代码来处理 HDFS 等分布式文件系统中的大型数据集。理解它的最简单方法是参考 “简单日志分析” 中的 Web 服务器日志分析示例。MapReduce 中的数据处理模式与此示例非常相似:
- 读取一组输入文件,并将其分解成 记录(records)。在 Web 服务器日志示例中,每条记录都是日志中的一行(即
\n是记录分隔符)。 - 调用 Mapper 函数,从每条输入记录中提取一对键值。在前面的例子中,Mapper 函数是
awk '{print $7}':它提取 URL($7)作为键,并将值留空。 - 按键排序所有的键值对。在日志的例子中,这由第一个
sort命令完成。 - 调用 Reducer 函数遍历排序后的键值对。如果同一个键出现多次,排序使它们在列表中相邻,所以很容易组合这些值而不必在内存中保留很多状态。在前面的例子中,Reducer 是由
uniq -c命令实现的,该命令使用相同的键来统计相邻记录的数量。
这四个步骤可以作为一个 MapReduce 作业执行。步骤 2(Map)和 4(Reduce)是你编写自定义数据处理代码的地方。步骤 1(将文件分解成记录)由输入格式解析器处理。步骤 3 中的排序步骤隐含在 MapReduce 中 —— 你不必编写它,因为 Mapper 的输出始终在送往 Reducer 之前进行排序。
要创建 MapReduce 作业,你需要实现两个回调函数,Mapper 和 Reducer,其行为如下(请参阅 “MapReduce 查询”):
Mapper
Mapper 会在每条输入记录上调用一次,其工作是从输入记录中提取键值。对于每个输入,它可以生成任意数量的键值对(包括 None)。它不会保留从一个输入记录到下一个记录的任何状态,因此每个记录都是独立处理的。
Reducer
MapReduce 框架拉取由 Mapper 生成的键值对,收集属于同一个键的所有值,并在这组值上迭代调用 Reducer。 Reducer 可以产生输出记录(例如相同 URL 的出现次数)。
在 Web 服务器日志的例子中,我们在第 5 步中有第二个 sort 命令,它按请求数对 URL 进行排序。在 MapReduce 中,如果你需要第二个排序阶段,则可以通过编写第二个 MapReduce 作业并将第一个作业的输出用作第二个作业的输入来实现它。这样看来,Mapper 的作用是将数据放入一个适合排序的表单中,并且 Reducer 的作用是处理已排序的数据。
分布式执行MapReduce
MapReduce 与 Unix 命令管道的主要区别在于,MapReduce 可以在多台机器上并行执行计算,而无需编写代码来显式处理并行问题。Mapper 和 Reducer 一次只能处理一条记录;它们不需要知道它们的输入来自哪里,或者输出去往什么地方,所以框架可以处理在机器之间移动数据的复杂性。
在分布式计算中可以使用标准的 Unix 工具作为 Mapper 和 Reducer【25】,但更常见的是,它们被实现为传统编程语言的函数。在 Hadoop MapReduce 中,Mapper 和 Reducer 都是实现特定接口的 Java 类。在 MongoDB 和 CouchDB 中,Mapper 和 Reducer 都是 JavaScript 函数(请参阅 “MapReduce 查询”)。
图 10-1 显示了 Hadoop MapReduce 作业中的数据流。其并行化基于分区(请参阅 第六章):作业的输入通常是 HDFS 中的一个目录,输入目录中的每个文件或文件块都被认为是一个单独的分区,可以单独处理 map 任务(图 10-1 中的 m1,m2 和 m3 标记)。
每个输入文件的大小通常是数百兆字节。 MapReduce 调度器(图中未显示)试图在其中一台存储输入文件副本的机器上运行每个 Mapper,只要该机器有足够的备用 RAM 和 CPU 资源来运行 Mapper 任务【26】。这个原则被称为 将计算放在数据附近【27】:它节省了通过网络复制输入文件的开销,减少网络负载并增加局部性。

图 10-1 具有三个 Mapper 和三个 Reducer 的 MapReduce 任务
在大多数情况下,应该在 Mapper 任务中运行的应用代码在将要运行它的机器上还不存在,所以 MapReduce 框架首先将代码(例如 Java 程序中的 JAR 文件)复制到适当的机器。然后启动 Map 任务并开始读取输入文件,一次将一条记录传入 Mapper 回调函数。Mapper 的输出由键值对组成。
计算的 Reduce 端也被分区。虽然 Map 任务的数量由输入文件块的数量决定,但 Reducer 的任务的数量是由作业作者配置的(它可以不同于 Map 任务的数量)。为了确保具有相同键的所有键值对最终落在相同的 Reducer 处,框架使用键的散列值来确定哪个 Reduce 任务应该接收到特定的键值对(请参阅 “根据键的散列分区”)。
键值对必须进行排序,但数据集可能太大,无法在单台机器上使用常规排序算法进行排序。相反,分类是分阶段进行的。首先每个 Map 任务都按照 Reducer 对输出进行分区。每个分区都被写入 Mapper 程序的本地磁盘,使用的技术与我们在 “SSTables 与 LSM 树” 中讨论的类似。
只要当 Mapper 读取完输入文件,并写完排序后的输出文件,MapReduce 调度器就会通知 Reducer 可以从该 Mapper 开始获取输出文件。Reducer 连接到每个 Mapper,并下载自己相应分区的有序键值对文件。按 Reducer 分区,排序,从 Mapper 向 Reducer 复制分区数据,这一整个过程被称为 混洗(shuffle)【26】(一个容易混淆的术语 —— 不像洗牌,在 MapReduce 中的混洗没有随机性)。
Reduce 任务从 Mapper 获取文件,并将它们合并在一起,并保留有序特性。因此,如果不同的 Mapper 生成了键相同的记录,则在 Reducer 的输入中,这些记录将会相邻。
Reducer 调用时会收到一个键,和一个迭代器作为参数,迭代器会顺序地扫过所有具有该键的记录(因为在某些情况可能无法完全放入内存中)。Reducer 可以使用任意逻辑来处理这些记录,并且可以生成任意数量的输出记录。这些输出记录会写入分布式文件系统上的文件中(通常是在跑 Reducer 的机器本地磁盘上留一份,并在其他机器上留几份副本)。
MapReduce工作流
单个 MapReduce 作业可以解决的问题范围很有限。以日志分析为例,单个 MapReduce 作业可以确定每个 URL 的页面浏览次数,但无法确定最常见的 URL,因为这需要第二轮排序。
因此将 MapReduce 作业链接成为 工作流(workflow) 中是极为常见的,例如,一个作业的输出成为下一个作业的输入。Hadoop MapReduce 框架对工作流没有特殊支持,所以这个链是通过目录名隐式实现的:第一个作业必须将其输出配置为 HDFS 中的指定目录,第二个作业必须将其输入配置为从同一个目录。从 MapReduce 框架的角度来看,这是两个独立的作业。
因此,被链接的 MapReduce 作业并没有那么像 Unix 命令管道(它直接将一个进程的输出作为另一个进程的输入,仅用一个很小的内存缓冲区)。它更像是一系列命令,其中每个命令的输出写入临时文件,下一个命令从临时文件中读取。这种设计有利也有弊,我们将在 “物化中间状态” 中讨论。
只有当作业成功完成后,批处理作业的输出才会被视为有效的(MapReduce 会丢弃失败作业的部分输出)。因此,工作流中的一项作业只有在先前的作业 —— 即生产其输入的作业 —— 成功完成后才能开始。为了处理这些作业之间的依赖,有很多针对 Hadoop 的工作流调度器被开发出来,包括 Oozie、Azkaban、Luigi、Airflow 和 Pinball 【28】。
这些调度程序还具有管理功能,在维护大量批处理作业时非常有用。在构建推荐系统时,由 50 到 100 个 MapReduce 作业组成的工作流是常见的【29】。而在大型组织中,许多不同的团队可能运行不同的作业来读取彼此的输出。工具支持对于管理这样复杂的数据流而言非常重要。
Hadoop 的各种高级工具(如 Pig 【30】、Hive 【31】、Cascading 【32】、Crunch 【33】和 FlumeJava 【34】)也能自动布线组装多个 MapReduce 阶段,生成合适的工作流。
Reduce侧连接与分组
我们在 第二章 中讨论了数据模型和查询语言的连接,但是我们还没有深入探讨连接是如何实现的。现在是我们再次捡起这条线索的时候了。
在许多数据集中,一条记录与另一条记录存在关联是很常见的:关系模型中的 外键,文档模型中的 文档引用 或图模型中的 边。当你需要同时访问这一关联的两侧(持有引用的记录与被引用的记录)时,连接就是必须的。正如 第二章 所讨论的,非规范化可以减少对连接的需求,但通常无法将其完全移除 [^v]。
[^v]: 我们在本书中讨论的连接通常是等值连接,即最常见的连接类型,其中记录通过与其他记录在特定字段(例如 ID)中具有 相同值 相关联。有些数据库支持更通用的连接类型,例如使用小于运算符而不是等号运算符,但是我们没有地方来讲这些东西。
在数据库中,如果执行只涉及少量记录的查询,数据库通常会使用 索引 来快速定位感兴趣的记录(请参阅 第三章)。如果查询涉及到连接,则可能涉及到查找多个索引。然而 MapReduce 没有索引的概念 —— 至少在通常意义上没有。
当 MapReduce 作业被赋予一组文件作为输入时,它读取所有这些文件的全部内容;数据库会将这种操作称为 全表扫描。如果你只想读取少量的记录,则全表扫描与索引查询相比,代价非常高昂。但是在分析查询中(请参阅 “事务处理还是分析?”),通常需要计算大量记录的聚合。在这种情况下,特别是如果能在多台机器上并行处理时,扫描整个输入可能是相当合理的事情。
当我们在批处理的语境中讨论连接时,我们指的是在数据集中解析某种关联的全量存在。 例如我们假设一个作业是同时处理所有用户的数据,而非仅仅是为某个特定用户查找数据(而这能通过索引更高效地完成)。
示例:用户活动事件分析
图 10-2 给出了一个批处理作业中连接的典型例子。左侧是事件日志,描述登录用户在网站上做的事情(称为 活动事件,即 activity events,或 点击流数据,即 clickstream data),右侧是用户数据库。 你可以将此示例看作是星型模式的一部分(请参阅 “星型和雪花型:分析的模式”):事件日志是事实表,用户数据库是其中的一个维度。
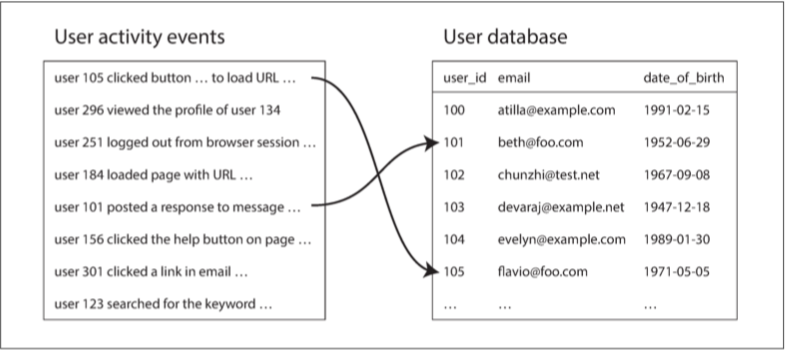
图 10-2 用户行为日志与用户档案的连接
分析任务可能需要将用户活动与用户档案信息相关联:例如,如果档案包含用户的年龄或出生日期,系统就可以确定哪些页面更受哪些年龄段的用户欢迎。然而活动事件仅包含用户 ID,而没有包含完整的用户档案信息。在每个活动事件中嵌入这些档案信息很可能会非常浪费。因此,活动事件需要与用户档案数据库相连接。
实现这一连接的最简单方法是,逐个遍历活动事件,并为每个遇到的用户 ID 查询用户数据库(在远程服务器上)。这是可能的,但是它的性能可能会非常差:处理吞吐量将受限于受数据库服务器的往返时间,本地缓存的有效性很大程度上取决于数据的分布,并行运行大量查询可能会轻易压垮数据库【35】。
为了在批处理过程中实现良好的吞吐量,计算必须(尽可能)限于单台机器上进行。为待处理的每条记录发起随机访问的网络请求实在是太慢了。而且,查询远程数据库意味着批处理作业变为 非确定的(nondeterministic),因为远程数据库中的数据可能会改变。
因此,更好的方法是获取用户数据库的副本(例如,使用 ETL 进程从数据库备份中提取数据,请参阅 “数据仓库”),并将它和用户行为日志放入同一个分布式文件系统中。然后你可以将用户数据库存储在 HDFS 中的一组文件中,而用户活动记录存储在另一组文件中,并能用 MapReduce 将所有相关记录集中到同一个地方进行高效处理。
排序合并连接
回想一下,Mapper 的目的是从每个输入记录中提取一对键值。在 图 10-2 的情况下,这个键就是用户 ID:一组 Mapper 会扫过活动事件(提取用户 ID 作为键,活动事件作为值),而另一组 Mapper 将会扫过用户数据库(提取用户 ID 作为键,用户的出生日期作为值)。这个过程如 图 10-3 所示。

图 10-3 在用户 ID 上进行的 Reduce 端连接。如果输入数据集分区为多个文件,则每个分区都会被多个 Mapper 并行处理
当 MapReduce 框架通过键对 Mapper 输出进行分区,然后对键值对进行排序时,效果是具有相同 ID 的所有活动事件和用户记录在 Reducer 输入中彼此相邻。 Map-Reduce 作业甚至可以也让这些记录排序,使 Reducer 总能先看到来自用户数据库的记录,紧接着是按时间戳顺序排序的活动事件 —— 这种技术被称为 二次排序(secondary sort)【26】。
然后 Reducer 可以容易地执行实际的连接逻辑:每个用户 ID 都会被调用一次 Reducer 函数,且因为二次排序,第一个值应该是来自用户数据库的出生日期记录。 Reducer 将出生日期存储在局部变量中,然后使用相同的用户 ID 遍历活动事件,输出 已观看网址 和 观看者年龄 的结果对。随后的 Map-Reduce 作业可以计算每个 URL 的查看者年龄分布,并按年龄段进行聚集。
由于 Reducer 一次处理一个特定用户 ID 的所有记录,因此一次只需要将一条用户记录保存在内存中,而不需要通过网络发出任何请求。这个算法被称为 排序合并连接(sort-merge join),因为 Mapper 的输出是按键排序的,然后 Reducer 将来自连接两侧的有序记录列表合并在一起。
把相关数据放在一起
在排序合并连接中,Mapper 和排序过程确保了所有对特定用户 ID 执行连接操作的必须数据都被放在同一个地方:单次调用 Reducer 的地方。预先排好了所有需要的数据,Reducer 可以是相当简单的单线程代码,能够以高吞吐量和与低内存开销扫过这些记录。
这种架构可以看做,Mapper 将 “消息” 发送给 Reducer。当一个 Mapper 发出一个键值对时,这个键的作用就像值应该传递到的目标地址。即使键只是一个任意的字符串(不是像 IP 地址和端口号那样的实际的网络地址),它表现的就像一个地址:所有具有相同键的键值对将被传递到相同的目标(一次 Reducer 的调用)。
使用 MapReduce 编程模型,能将计算的物理网络通信层面(从正确的机器获取数据)从应用逻辑中剥离出来(获取数据后执行处理)。这种分离与数据库的典型用法形成了鲜明对比,从数据库中获取数据的请求经常出现在应用代码内部【36】。由于 MapReduce 处理了所有的网络通信,因此它也避免了让应用代码去担心部分故障,例如另一个节点的崩溃:MapReduce 在不影响应用逻辑的情况下能透明地重试失败的任务。
分组
除了连接之外,“把相关数据放在一起” 的另一种常见模式是,按某个键对记录分组(如 SQL 中的 GROUP BY 子句)。所有带有相同键的记录构成一个组,而下一步往往是在每个组内进行某种聚合操作,例如:
- 统计每个组中记录的数量(例如在统计 PV 的例子中,在 SQL 中表示为
COUNT(*)聚合) - 对某个特定字段求和(SQL 中的
SUM(fieldname)) - 按某种分级函数取出排名前 k 条记录。
使用 MapReduce 实现这种分组操作的最简单方法是设置 Mapper,以便它们生成的键值对使用所需的分组键。然后分区和排序过程将所有具有相同分区键的记录导向同一个 Reducer。因此在 MapReduce 之上实现分组和连接看上去非常相似。
分组的另一个常见用途是整理特定用户会话的所有活动事件,以找出用户进行的一系列操作(称为 会话化(sessionization)【37】)。例如,可以使用这种分析来确定显示新版网站的用户是否比那些显示旧版本的用户更有购买欲(A/B 测试),或者计算某个营销活动是否值得。
如果你有多个 Web 服务器处理用户请求,则特定用户的活动事件很可能分散在各个不同的服务器的日志文件中。你可以通过使用会话 cookie,用户 ID 或类似的标识符作为分组键,以将特定用户的所有活动事件放在一起来实现会话化,与此同时,不同用户的事件仍然散布在不同的分区中。
处理偏斜
如果存在与单个键关联的大量数据,则 “将具有相同键的所有记录放到相同的位置” 这种模式就被破坏了。例如在社交网络中,大多数用户可能会与几百人有连接,但少数名人可能有数百万的追随者。这种不成比例的活动数据库记录被称为 关键对象(linchpin object)【38】或 热键(hot key)。
在单个 Reducer 中收集与某个名人相关的所有活动(例如他们发布内容的回复)可能导致严重的 偏斜(也称为 热点,即 hot spot)—— 也就是说,一个 Reducer 必须比其他 Reducer 处理更多的记录(请参阅 “负载偏斜与热点消除“)。由于 MapReduce 作业只有在所有 Mapper 和 Reducer 都完成时才完成,所有后续作业必须等待最慢的 Reducer 才能启动。
如果连接的输入存在热键,可以使用一些算法进行补偿。例如,Pig 中的 偏斜连接(skewed join) 方法首先运行一个抽样作业(Sampling Job)来确定哪些键是热键【39】。连接实际执行时,Mapper 会将热键的关联记录 随机(相对于传统 MapReduce 基于键散列的确定性方法)发送到几个 Reducer 之一。对于另外一侧的连接输入,与热键相关的记录需要被复制到 所有 处理该键的 Reducer 上【40】。
这种技术将处理热键的工作分散到多个 Reducer 上,这样可以使其更好地并行化,代价是需要将连接另一侧的输入记录复制到多个 Reducer 上。 Crunch 中的 分片连接(sharded join) 方法与之类似,但需要显式指定热键而不是使用抽样作业。这种技术也非常类似于我们在 “负载偏斜与热点消除” 中讨论的技术,使用随机化来缓解分区数据库中的热点。
Hive 的偏斜连接优化采取了另一种方法。它需要在表格元数据中显式指定热键,并将与这些键相关的记录单独存放,与其它文件分开。当在该表上执行连接时,对于热键,它会使用 Map 端连接(请参阅下一节)。
当按照热键进行分组并聚合时,可以将分组分两个阶段进行。第一个 MapReduce 阶段将记录发送到随机 Reducer,以便每个 Reducer 只对热键的子集执行分组,为每个键输出一个更紧凑的中间聚合结果。然后第二个 MapReduce 作业将所有来自第一阶段 Reducer 的中间聚合结果合并为每个键一个值。
Map侧连接
上一节描述的连接算法在 Reducer 中执行实际的连接逻辑,因此被称为 Reduce 侧连接。Mapper 扮演着预处理输入数据的角色:从每个输入记录中提取键值,将键值对分配给 Reducer 分区,并按键排序。
Reduce 侧方法的优点是不需要对输入数据做任何假设:无论其属性和结构如何,Mapper 都可以对其预处理以备连接。然而不利的一面是,排序,复制至 Reducer,以及合并 Reducer 输入,所有这些操作可能开销巨大。当数据通过 MapReduce 阶段时,数据可能需要落盘好几次,取决于可用的内存缓冲区【37】。
另一方面,如果你 能 对输入数据作出某些假设,则通过使用所谓的 Map 侧连接来加快连接速度是可行的。这种方法使用了一个裁减掉 Reducer 与排序的 MapReduce 作业,每个 Mapper 只是简单地从分布式文件系统中读取一个输入文件块,然后将输出文件写入文件系统,仅此而已。
广播散列连接
适用于执行 Map 端连接的最简单场景是大数据集与小数据集连接的情况。要点在于小数据集需要足够小,以便可以将其全部加载到每个 Mapper 的内存中。
例如,假设在 图 10-2 的情况下,用户数据库小到足以放进内存中。在这种情况下,当 Mapper 启动时,它可以首先将用户数据库从分布式文件系统读取到内存中的散列表中。完成此操作后,Mapper 可以扫描用户活动事件,并简单地在散列表中查找每个事件的用户 ID [^vi]。
[^vi]: 这个例子假定散列表中的每个键只有一个条目,这对用户数据库(用户 ID 唯一标识一个用户)可能是正确的。通常,哈希表可能需要包含具有相同键的多个条目,而连接运算符将对每个键输出所有的匹配。
参与连接的较大输入的每个文件块各有一个 Mapper(在 图 10-2 的例子中活动事件是较大的输入)。每个 Mapper 都会将较小输入整个加载到内存中。
这种简单有效的算法被称为 广播散列连接(broadcast hash join):广播 一词反映了这样一个事实,每个连接较大输入端分区的 Mapper 都会将较小输入端数据集整个读入内存中(所以较小输入实际上 “广播” 到较大数据的所有分区上),散列 一词反映了它使用一个散列表。 Pig(名为 “复制链接(replicated join)”),Hive(“MapJoin”),Cascading 和 Crunch 支持这种连接。它也被诸如 Impala 的数据仓库查询引擎使用【41】。
除了将较小的连接输入加载到内存散列表中,另一种方法是将较小输入存储在本地磁盘上的只读索引中【42】。索引中经常使用的部分将保留在操作系统的页面缓存中,因而这种方法可以提供与内存散列表几乎一样快的随机查找性能,但实际上并不需要数据集能放入内存中。
分区散列连接
如果 Map 侧连接的输入以相同的方式进行分区,则散列连接方法可以独立应用于每个分区。在 图 10-2 的情况中,你可以根据用户 ID 的最后一位十进制数字来对活动事件和用户数据库进行分区(因此连接两侧各有 10 个分区)。例如,Mapper3 首先将所有具有以 3 结尾的 ID 的用户加载到散列表中,然后扫描 ID 为 3 的每个用户的所有活动事件。
如果分区正确无误,可以确定的是,所有你可能需要连接的记录都落在同一个编号的分区中。因此每个 Mapper 只需要从输入两端各读取一个分区就足够了。好处是每个 Mapper 都可以在内存散列表中少放点数据。
这种方法只有当连接两端输入有相同的分区数,且两侧的记录都是使用相同的键与相同的哈希函数做分区时才适用。如果输入是由之前执行过这种分组的 MapReduce 作业生成的,那么这可能是一个合理的假设。
分区散列连接在 Hive 中称为 Map 侧桶连接(bucketed map joins)【37】。
Map侧合并连接
如果输入数据集不仅以相同的方式进行分区,而且还基于相同的键进行 排序,则可适用另一种 Map 侧连接的变体。在这种情况下,输入是否小到能放入内存并不重要,因为这时候 Mapper 同样可以执行归并操作(通常由 Reducer 执行)的归并操作:按键递增的顺序依次读取两个输入文件,将具有相同键的记录配对。
如果能进行 Map 侧合并连接,这通常意味着前一个 MapReduce 作业可能一开始就已经把输入数据做了分区并进行了排序。原则上这个连接就可以在前一个作业的 Reduce 阶段进行。但使用独立的仅 Map 作业有时也是合适的,例如,分好区且排好序的中间数据集可能还会用于其他目的。
MapReduce工作流与Map侧连接
当下游作业使用 MapReduce 连接的输出时,选择 Map 侧连接或 Reduce 侧连接会影响输出的结构。Reduce 侧连接的输出是按照 连接键 进行分区和排序的,而 Map 端连接的输出则按照与较大输入相同的方式进行分区和排序(因为无论是使用分区连接还是广播连接,连接较大输入端的每个文件块都会启动一个 Map 任务)。
如前所述,Map 侧连接也对输入数据集的大小,有序性和分区方式做出了更多假设。在优化连接策略时,了解分布式文件系统中数据集的物理布局变得非常重要:仅仅知道编码格式和数据存储目录的名称是不够的;你还必须知道数据是按哪些键做的分区和排序,以及分区的数量。
在 Hadoop 生态系统中,这种关于数据集分区的元数据通常在 HCatalog 和 Hive Metastore 中维护【37】。
批处理工作流的输出
我们已经说了很多用于实现 MapReduce 工作流的算法,但却忽略了一个重要的问题:这些处理完成之后的最终结果是什么?我们最开始为什么要跑这些作业?
在数据库查询的场景中,我们将事务处理(OLTP)与分析两种目的区分开来(请参阅 “事务处理还是分析?”)。我们看到,OLTP 查询通常根据键查找少量记录,使用索引,并将其呈现给用户(比如在网页上)。另一方面,分析查询通常会扫描大量记录,执行分组与聚合,输出通常有着报告的形式:显示某个指标随时间变化的图表,或按照某种排位取前 10 项,或将一些数字细化为子类。这种报告的消费者通常是需要做出商业决策的分析师或经理。
批处理放哪里合适?它不属于事务处理,也不是分析。它和分析比较接近,因为批处理通常会扫过输入数据集的绝大部分。然而 MapReduce 作业工作流与用于分析目的的 SQL 查询是不同的(请参阅 “Hadoop 与分布式数据库的对比”)。批处理过程的输出通常不是报表,而是一些其他类型的结构。
建立搜索索引
Google 最初使用 MapReduce 是为其搜索引擎建立索引,其实现为由 5 到 10 个 MapReduce 作业组成的工作流【1】。虽然 Google 后来也不仅仅是为这个目的而使用 MapReduce 【43】,但如果从构建搜索索引的角度来看,更能帮助理解 MapReduce。 (直至今日,Hadoop MapReduce 仍然是为 Lucene/Solr 构建索引的好方法【44】)
我们在 “全文搜索和模糊索引” 中简要地了解了 Lucene 这样的全文搜索索引是如何工作的:它是一个文件(关键词字典),你可以在其中高效地查找特定关键字,并找到包含该关键字的所有文档 ID 列表(文章列表)。这是一种非常简化的看法 —— 实际上,搜索索引需要各种额外数据,以便根据相关性对搜索结果进行排名、纠正拼写错误、解析同义词等等 —— 但这个原则是成立的。
如果需要对一组固定文档执行全文搜索,则批处理是一种构建索引的高效方法:Mapper 根据需要对文档集合进行分区,每个 Reducer 构建该分区的索引,并将索引文件写入分布式文件系统。构建这样的文档分区索引(请参阅 “分区与次级索引”)并行处理效果拔群。
由于按关键字查询搜索索引是只读操作,因而这些索引文件一旦创建就是不可变的。
如果索引的文档集合发生更改,一种选择是定期重跑整个索引工作流,并在完成后用新的索引文件批量替换以前的索引文件。如果只有少量的文档发生了变化,这种方法的计算成本可能会很高。但它的优点是索引过程很容易理解:文档进,索引出。
另一个选择是,可以增量建立索引。如 第三章 中讨论的,如果要在索引中添加,删除或更新文档,Lucene 会写新的段文件,并在后台异步合并压缩段文件。我们将在 第十一章 中看到更多这种增量处理。
键值存储作为批处理输出
搜索索引只是批处理工作流可能输出的一个例子。批处理的另一个常见用途是构建机器学习系统,例如分类器(比如垃圾邮件过滤器,异常检测,图像识别)与推荐系统(例如,你可能认识的人,你可能感兴趣的产品或相关的搜索【29】)。
这些批处理作业的输出通常是某种数据库:例如,可以通过给定用户 ID 查询该用户推荐好友的数据库,或者可以通过产品 ID 查询相关产品的数据库【45】。
这些数据库需要被处理用户请求的 Web 应用所查询,而它们通常是独立于 Hadoop 基础设施的。那么批处理过程的输出如何回到 Web 应用可以查询的数据库中呢?
最直接的选择可能是,直接在 Mapper 或 Reducer 中使用你最爱的数据库的客户端库,并从批处理作业直接写入数据库服务器,一次写入一条记录。它能工作(假设你的防火墙规则允许从你的 Hadoop 环境直接访问你的生产数据库),但这并不是一个好主意,出于以下几个原因:
- 正如前面在连接的上下文中讨论的那样,为每条记录发起一个网络请求,要比批处理任务的正常吞吐量慢几个数量级。即使客户端库支持批处理,性能也可能很差。
- MapReduce 作业经常并行运行许多任务。如果所有 Mapper 或 Reducer 都同时写入相同的输出数据库,并以批处理的预期速率工作,那么该数据库很可能被轻易压垮,其查询性能可能变差。这可能会导致系统其他部分的运行问题【35】。
- 通常情况下,MapReduce 为作业输出提供了一个干净利落的 “全有或全无” 保证:如果作业成功,则结果就是每个任务恰好执行一次所产生的输出,即使某些任务失败且必须一路重试。如果整个作业失败,则不会生成输出。然而从作业内部写入外部系统,会产生外部可见的副作用,这种副作用是不能以这种方式被隐藏的。因此,你不得不去操心对其他系统可见的部分完成的作业结果,并需要理解 Hadoop 任务尝试与预测执行的复杂性。
更好的解决方案是在批处理作业 内 创建一个全新的数据库,并将其作为文件写入分布式文件系统中作业的输出目录,就像上节中的搜索索引一样。这些数据文件一旦写入就是不可变的,可以批量加载到处理只读查询的服务器中。不少键值存储都支持在 MapReduce 作业中构建数据库文件,包括 Voldemort 【46】、Terrapin 【47】、ElephantDB 【48】和 HBase 批量加载【49】。
构建这些数据库文件是 MapReduce 的一种好用法:使用 Mapper 提取出键并按该键排序,已经完成了构建索引所必需的大量工作。由于这些键值存储大多都是只读的(文件只能由批处理作业一次性写入,然后就不可变),所以数据结构非常简单。比如它们就不需要预写式日志(WAL,请参阅 “让 B 树更可靠”)。
将数据加载到 Voldemort 时,服务器将继续用旧数据文件服务请求,同时将新数据文件从分布式文件系统复制到服务器的本地磁盘。一旦复制完成,服务器会自动将查询切换到新文件。如果在这个过程中出现任何问题,它可以轻易回滚至旧文件,因为它们仍然存在而且不可变【46】。
批处理输出的哲学
本章前面讨论过的 Unix 哲学(“Unix 哲学”)鼓励以显式指明数据流的方式进行实验:程序读取输入并写入输出。在这一过程中,输入保持不变,任何先前的输出都被新输出完全替换,且没有其他副作用。这意味着你可以随心所欲地重新运行一个命令,略做改动或进行调试,而不会搅乱系统的状态。
MapReduce 作业的输出处理遵循同样的原理。通过将输入视为不可变且避免副作用(如写入外部数据库),批处理作业不仅实现了良好的性能,而且更容易维护:
- 如果在代码中引入了一个错误,而输出错误或损坏了,则可以简单地回滚到代码的先前版本,然后重新运行该作业,输出将重新被纠正。或者,甚至更简单,你可以将旧的输出保存在不同的目录中,然后切换回原来的目录。具有读写事务的数据库没有这个属性:如果你部署了错误的代码,将错误的数据写入数据库,那么回滚代码将无法修复数据库中的数据。 (能够从错误代码中恢复的概念被称为 人类容错(human fault tolerance)【50】)
- 由于回滚很容易,比起在错误意味着不可挽回的伤害的环境,功能开发进展能快很多。这种 最小化不可逆性(minimizing irreversibility) 的原则有利于敏捷软件开发【51】。
- 如果 Map 或 Reduce 任务失败,MapReduce 框架将自动重新调度,并在同样的输入上再次运行它。如果失败是由代码中的错误造成的,那么它会不断崩溃,并最终导致作业在几次尝试之后失败。但是如果故障是由于临时问题导致的,那么故障就会被容忍。因为输入不可变,这种自动重试是安全的,而失败任务的输出会被 MapReduce 框架丢弃。
- 同一组文件可用作各种不同作业的输入,包括计算指标的监控作业并且评估作业的输出是否具有预期的性质(例如,将其与前一次运行的输出进行比较并测量差异) 。
- 与 Unix 工具类似,MapReduce 作业将逻辑与布线(配置输入和输出目录)分离,这使得关注点分离,可以重用代码:一个团队可以专注实现一个做好一件事的作业;而其他团队可以决定何时何地运行这项作业。
在这些领域,在 Unix 上表现良好的设计原则似乎也适用于 Hadoop,但 Unix 和 Hadoop 在某些方面也有所不同。例如,因为大多数 Unix 工具都假设输入输出是无类型文本文件,所以它们必须做大量的输入解析工作(本章开头的日志分析示例使用 {print $7} 来提取 URL)。在 Hadoop 上可以通过使用更结构化的文件格式消除一些低价值的语法转换:比如 Avro(请参阅 “Avro”)和 Parquet(请参阅 “列式存储”)经常使用,因为它们提供了基于模式的高效编码,并允许模式随时间推移而演进(见 第四章)。
Hadoop与分布式数据库的对比
正如我们所看到的,Hadoop 有点像 Unix 的分布式版本,其中 HDFS 是文件系统,而 MapReduce 是 Unix 进程的怪异实现(总是在 Map 阶段和 Reduce 阶段运行 sort 工具)。我们了解了如何在这些原语的基础上实现各种连接和分组操作。
当 MapReduce 论文发表时【1】,它从某种意义上来说 —— 并不新鲜。我们在前几节中讨论的所有处理和并行连接算法已经在十多年前所谓的 大规模并行处理(MPP, massively parallel processing) 数据库中实现了【3,40】。比如 Gamma database machine、Teradata 和 Tandem NonStop SQL 就是这方面的先驱【52】。
最大的区别是,MPP 数据库专注于在一组机器上并行执行分析 SQL 查询,而 MapReduce 和分布式文件系统【19】的组合则更像是一个可以运行任意程序的通用操作系统。
存储多样性
数据库要求你根据特定的模型(例如关系或文档)来构造数据,而分布式文件系统中的文件只是字节序列,可以使用任何数据模型和编码来编写。它们可能是数据库记录的集合,但同样可以是文本、图像、视频、传感器读数、稀疏矩阵、特征向量、基因组序列或任何其他类型的数据。
说白了,Hadoop 开放了将数据不加区分地转储到 HDFS 的可能性,允许后续再研究如何进一步处理【53】。相比之下,在将数据导入数据库专有存储格式之前,MPP 数据库通常需要对数据和查询模式进行仔细的前期建模。
在纯粹主义者看来,这种仔细的建模和导入似乎是可取的,因为这意味着数据库的用户有更高质量的数据来处理。然而实践经验表明,简单地使数据快速可用 —— 即使它很古怪,难以使用,使用原始格式 —— 也通常要比事先决定理想数据模型要更有价值【54】。
这个想法与数据仓库类似(请参阅 “数据仓库”):将大型组织的各个部分的数据集中在一起是很有价值的,因为它可以跨越以前相互分离的数据集进行连接。 MPP 数据库所要求的谨慎模式设计拖慢了集中式数据收集速度;以原始形式收集数据,稍后再操心模式的设计,能使数据收集速度加快(有时被称为 “数据湖(data lake)” 或 “企业数据中心(enterprise data hub)”【55】)。
不加区分的数据转储转移了解释数据的负担:数据集的生产者不再需要强制将其转化为标准格式,数据的解释成为消费者的问题(读时模式 方法【56】;请参阅 “文档模型中的模式灵活性”)。如果生产者和消费者是不同优先级的不同团队,这可能是一种优势。甚至可能不存在一个理想的数据模型,对于不同目的有不同的合适视角。以原始形式简单地转储数据,可以允许多种这样的转换。这种方法被称为 寿司原则(sushi principle):“原始数据更好”【57】。
因此,Hadoop 经常被用于实现 ETL 过程(请参阅 “数据仓库”):事务处理系统中的数据以某种原始形式转储到分布式文件系统中,然后编写 MapReduce 作业来清理数据,将其转换为关系形式,并将其导入 MPP 数据仓库以进行分析。数据建模仍然在进行,但它在一个单独的步骤中进行,与数据收集相解耦。这种解耦是可行的,因为分布式文件系统支持以任何格式编码的数据。
处理模型的多样性
MPP 数据库是单体的,紧密集成的软件,负责磁盘上的存储布局,查询计划,调度和执行。由于这些组件都可以针对数据库的特定需求进行调整和优化,因此整个系统可以在其设计针对的查询类型上取得非常好的性能。而且,SQL 查询语言允许以优雅的语法表达查询,而无需编写代码,可以在业务分析师使用的可视化工具(例如 Tableau)中访问到。
另一方面,并非所有类型的处理都可以合理地表达为 SQL 查询。例如,如果要构建机器学习和推荐系统,或者使用相关性排名模型的全文搜索索引,或者执行图像分析,则很可能需要更一般的数据处理模型。这些类型的处理通常是特别针对特定应用的(例如机器学习的特征工程,机器翻译的自然语言模型,欺诈预测的风险评估函数),因此它们不可避免地需要编写代码,而不仅仅是查询。
MapReduce 使工程师能够轻松地在大型数据集上运行自己的代码。如果你有 HDFS 和 MapReduce,那么你 可以 在它之上建立一个 SQL 查询执行引擎,事实上这正是 Hive 项目所做的【31】。但是,你也可以编写许多其他形式的批处理,这些批处理不必非要用 SQL 查询表示。
随后,人们发现 MapReduce 对于某些类型的处理而言局限性很大,表现很差,因此在 Hadoop 之上其他各种处理模型也被开发出来(我们将在 “MapReduce 之后” 中看到其中一些)。只有两种处理模型,SQL 和 MapReduce,还不够,需要更多不同的模型!而且由于 Hadoop 平台的开放性,实施一整套方法是可行的,而这在单体 MPP 数据库的范畴内是不可能的【58】。
至关重要的是,这些不同的处理模型都可以在共享的单个机器集群上运行,所有这些机器都可以访问分布式文件系统上的相同文件。在 Hadoop 方式中,不需要将数据导入到几个不同的专用系统中进行不同类型的处理:系统足够灵活,可以支持同一个集群内不同的工作负载。不需要移动数据,使得从数据中挖掘价值变得容易得多,也使采用新的处理模型容易的多。
Hadoop 生态系统包括随机访问的 OLTP 数据库,如 HBase(请参阅 “SSTables 和 LSM 树”)和 MPP 风格的分析型数据库,如 Impala 【41】。 HBase 与 Impala 都不使用 MapReduce,但都使用 HDFS 进行存储。它们是迥异的数据访问与处理方法,但是它们可以共存,并被集成到同一个系统中。
针对频繁故障设计
当比较 MapReduce 和 MPP 数据库时,两种不同的设计思路出现了:处理故障和使用内存与磁盘的方式。与在线系统相比,批处理对故障不太敏感,因为就算失败也不会立即影响到用户,而且它们总是能再次运行。
如果一个节点在执行查询时崩溃,大多数 MPP 数据库会中止整个查询,并让用户重新提交查询或自动重新运行它【3】。由于查询通常最多运行几秒钟或几分钟,所以这种错误处理的方法是可以接受的,因为重试的代价不是太大。 MPP 数据库还倾向于在内存中保留尽可能多的数据(例如,使用散列连接)以避免从磁盘读取的开销。
另一方面,MapReduce 可以容忍单个 Map 或 Reduce 任务的失败,而不会影响作业的整体,通过以单个任务的粒度重试工作。它也会非常急切地将数据写入磁盘,一方面是为了容错,另一部分是因为假设数据集太大而不能适应内存。
MapReduce 方式更适用于较大的作业:要处理如此之多的数据并运行很长时间的作业,以至于在此过程中很可能至少遇到一个任务故障。在这种情况下,由于单个任务失败而重新运行整个作业将是非常浪费的。即使以单个任务的粒度进行恢复引入了使得无故障处理更慢的开销,但如果任务失败率足够高,这仍然是一种合理的权衡。
但是这些假设有多么现实呢?在大多数集群中,机器故障确实会发生,但是它们不是很频繁 —— 可能少到绝大多数作业都不会经历机器故障。为了容错,真的值得带来这么大的额外开销吗?
要了解 MapReduce 节约使用内存和在任务的层次进行恢复的原因,了解最初设计 MapReduce 的环境是很有帮助的。Google 有着混用的数据中心,在线生产服务和离线批处理作业在同样机器上运行。每个任务都有一个通过容器强制执行的资源配给(CPU 核心、RAM、磁盘空间等)。每个任务也具有优先级,如果优先级较高的任务需要更多的资源,则可以终止(抢占)同一台机器上较低优先级的任务以释放资源。优先级还决定了计算资源的定价:团队必须为他们使用的资源付费,而优先级更高的进程花费更多【59】。
这种架构允许非生产(低优先级)计算资源被 过量使用(overcommitted),因为系统知道必要时它可以回收资源。与分离生产和非生产任务的系统相比,过量使用资源可以更好地利用机器并提高效率。但由于 MapReduce 作业以低优先级运行,它们随时都有被抢占的风险,因为优先级较高的进程可能需要其资源。在高优先级进程拿走所需资源后,批量作业能有效地 “捡面包屑”,利用剩下的任何计算资源。
在谷歌,运行一个小时的 MapReduce 任务有大约有 5% 的风险被终止,为了给更高优先级的进程挪地方。这一概率比硬件问题、机器重启或其他原因的概率高了一个数量级【59】。按照这种抢占率,如果一个作业有 100 个任务,每个任务运行 10 分钟,那么至少有一个任务在完成之前被终止的风险大于 50%。
这就是 MapReduce 被设计为容忍频繁意外任务终止的原因:不是因为硬件很不可靠,而是因为任意终止进程的自由有利于提高计算集群中的资源利用率。
在开源的集群调度器中,抢占的使用较少。 YARN 的 CapacityScheduler 支持抢占,以平衡不同队列的资源分配【58】,但在编写本文时,YARN,Mesos 或 Kubernetes 不支持通用的优先级抢占【60】。在任务不经常被终止的环境中,MapReduce 的这一设计决策就没有多少意义了。在下一节中,我们将研究一些与 MapReduce 设计决策相异的替代方案。
MapReduce之后
虽然 MapReduce 在 2000 年代后期变得非常流行,并受到大量的炒作,但它只是分布式系统的许多可能的编程模型之一。对于不同的数据量,数据结构和处理类型,其他工具可能更适合表示计算。
不管如何,我们在这一章花了大把时间来讨论 MapReduce,因为它是一种有用的学习工具,它是分布式文件系统的一种相当简单明晰的抽象。在这里,简单 意味着我们能理解它在做什么,而不是意味着使用它很简单。恰恰相反:使用原始的 MapReduce API 来实现复杂的处理工作实际上是非常困难和费力的 —— 例如,任意一种连接算法都需要你从头开始实现【37】。
针对直接使用 MapReduce 的困难,在 MapReduce 上有很多高级编程模型(Pig、Hive、Cascading、Crunch)被创造出来,作为建立在 MapReduce 之上的抽象。如果你了解 MapReduce 的原理,那么它们学起来相当简单。而且它们的高级结构能显著简化许多常见批处理任务的实现。
但是,MapReduce 执行模型本身也存在一些问题,这些问题并没有通过增加另一个抽象层次而解决,而对于某些类型的处理,它表现得非常差劲。一方面,MapReduce 非常稳健:你可以使用它在任务会频繁终止的多租户系统上处理几乎任意大量级的数据,并且仍然可以完成工作(虽然速度很慢)。另一方面,对于某些类型的处理而言,其他工具有时会快上几个数量级。
在本章的其余部分中,我们将介绍一些批处理方法。在 第十一章 我们将转向流处理,它可以看作是加速批处理的另一种方法。
物化中间状态
如前所述,每个 MapReduce 作业都独立于其他任何作业。作业与世界其他地方的主要连接点是分布式文件系统上的输入和输出目录。如果希望一个作业的输出成为第二个作业的输入,则需要将第二个作业的输入目录配置为第一个作业输出目录,且外部工作流调度程序必须在第一个作业完成后再启动第二个。
如果第一个作业的输出是要在组织内广泛发布的数据集,则这种配置是合理的。在这种情况下,你需要通过名称引用它,并将其重用为多个不同作业的输入(包括由其他团队开发的作业)。将数据发布到分布式文件系统中众所周知的位置能够带来 松耦合,这样作业就不需要知道是谁在提供输入或谁在消费输出(请参阅 “逻辑与布线相分离”)。
但在很多情况下,你知道一个作业的输出只能用作另一个作业的输入,这些作业由同一个团队维护。在这种情况下,分布式文件系统上的文件只是简单的 中间状态(intermediate state):一种将数据从一个作业传递到下一个作业的方式。在一个用于构建推荐系统的,由 50 或 100 个 MapReduce 作业组成的复杂工作流中,存在着很多这样的中间状态【29】。
将这个中间状态写入文件的过程称为 物化(materialization)。 (在 “聚合:数据立方体和物化视图” 中已经在物化视图的背景中遇到过这个术语。它意味着对某个操作的结果立即求值并写出来,而不是在请求时按需计算)
作为对照,本章开头的日志分析示例使用 Unix 管道将一个命令的输出与另一个命令的输入连接起来。管道并没有完全物化中间状态,而是只使用一个小的内存缓冲区,将输出增量地 流(stream) 向输入。
与 Unix 管道相比,MapReduce 完全物化中间状态的方法存在不足之处:
- MapReduce 作业只有在前驱作业(生成其输入)中的所有任务都完成时才能启动,而由 Unix 管道连接的进程会同时启动,输出一旦生成就会被消费。不同机器上的数据偏斜或负载不均意味着一个作业往往会有一些掉队的任务,比其他任务要慢得多才能完成。必须等待至前驱作业的所有任务完成,拖慢了整个工作流程的执行。
- Mapper 通常是多余的:它们仅仅是读取刚刚由 Reducer 写入的同样文件,为下一个阶段的分区和排序做准备。在许多情况下,Mapper 代码可能是前驱 Reducer 的一部分:如果 Reducer 和 Mapper 的输出有着相同的分区与排序方式,那么 Reducer 就可以直接串在一起,而不用与 Mapper 相互交织。
- 将中间状态存储在分布式文件系统中意味着这些文件被复制到多个节点,对这些临时数据这么搞就比较过分了。
数据流引擎
为了解决 MapReduce 的这些问题,几种用于分布式批处理的新执行引擎被开发出来,其中最著名的是 Spark 【61,62】,Tez 【63,64】和 Flink 【65,66】。它们的设计方式有很多区别,但有一个共同点:把整个工作流作为单个作业来处理,而不是把它分解为独立的子作业。
由于它们将工作流显式建模为数据从几个处理阶段穿过,所以这些系统被称为 数据流引擎(dataflow engines)。像 MapReduce 一样,它们在一条线上通过反复调用用户定义的函数来一次处理一条记录,它们通过输入分区来并行化载荷,它们通过网络将一个函数的输出复制到另一个函数的输入。
与 MapReduce 不同,这些函数不需要严格扮演交织的 Map 与 Reduce 的角色,而是可以以更灵活的方式进行组合。我们称这些函数为 算子(operators),数据流引擎提供了几种不同的选项来将一个算子的输出连接到另一个算子的输入:
- 一种选项是对记录按键重新分区并排序,就像在 MapReduce 的混洗阶段一样(请参阅 “分布式执行 MapReduce”)。这种功能可以用于实现排序合并连接和分组,就像在 MapReduce 中一样。
- 另一种可能是接受多个输入,并以相同的方式进行分区,但跳过排序。当记录的分区重要但顺序无关紧要时,这省去了分区散列连接的工作,因为构建散列表还是会把顺序随机打乱。
- 对于广播散列连接,可以将一个算子的输出,发送到连接算子的所有分区。
这种类型的处理引擎是基于像 Dryad【67】和 Nephele【68】这样的研究系统,与 MapReduce 模型相比,它有几个优点:
- 排序等昂贵的工作只需要在实际需要的地方执行,而不是默认地在每个 Map 和 Reduce 阶段之间出现。
- 没有不必要的 Map 任务,因为 Mapper 所做的工作通常可以合并到前面的 Reduce 算子中(因为 Mapper 不会更改数据集的分区)。
- 由于工作流中的所有连接和数据依赖都是显式声明的,因此调度程序能够总览全局,知道哪里需要哪些数据,因而能够利用局部性进行优化。例如,它可以尝试将消费某些数据的任务放在与生成这些数据的任务相同的机器上,从而数据可以通过共享内存缓冲区传输,而不必通过网络复制。
- 通常,算子间的中间状态足以保存在内存中或写入本地磁盘,这比写入 HDFS 需要更少的 I/O(必须将其复制到多台机器,并将每个副本写入磁盘)。 MapReduce 已经对 Mapper 的输出做了这种优化,但数据流引擎将这种思想推广至所有的中间状态。
- 算子可以在输入就绪后立即开始执行;后续阶段无需等待前驱阶段整个完成后再开始。
- 与 MapReduce(为每个任务启动一个新的 JVM)相比,现有 Java 虚拟机(JVM)进程可以重用来运行新算子,从而减少启动开销。
你可以使用数据流引擎执行与 MapReduce 工作流同样的计算,而且由于此处所述的优化,通常执行速度要明显快得多。既然算子是 Map 和 Reduce 的泛化,那么相同的处理代码就可以在任一执行引擎上运行:Pig,Hive 或 Cascading 中实现的工作流可以无需修改代码,可以通过修改配置,简单地从 MapReduce 切换到 Tez 或 Spark【64】。
Tez 是一个相当薄的库,它依赖于 YARN shuffle 服务来实现节点间数据的实际复制【58】,而 Spark 和 Flink 则是包含了独立网络通信层,调度器,及用户向 API 的大型框架。我们将简要讨论这些高级 API。
容错
完全物化中间状态至分布式文件系统的一个优点是,它具有持久性,这使得 MapReduce 中的容错相当容易:如果一个任务失败,它可以在另一台机器上重新启动,并从文件系统重新读取相同的输入。
Spark、Flink 和 Tez 避免将中间状态写入 HDFS,因此它们采取了不同的方法来容错:如果一台机器发生故障,并且该机器上的中间状态丢失,则它会从其他仍然可用的数据重新计算(在可行的情况下是先前的中间状态,要么就只能是原始输入数据,通常在 HDFS 上)。
为了实现这种重新计算,框架必须跟踪一个给定的数据是如何计算的 —— 使用了哪些输入分区?应用了哪些算子? Spark 使用 弹性分布式数据集(RDD,Resilient Distributed Dataset) 的抽象来跟踪数据的谱系【61】,而 Flink 对算子状态存档,允许恢复运行在执行过程中遇到错误的算子【66】。
在重新计算数据时,重要的是要知道计算是否是 确定性的:也就是说,给定相同的输入数据,算子是否始终产生相同的输出?如果一些丢失的数据已经发送给下游算子,这个问题就很重要。如果算子重新启动,重新计算的数据与原有的丢失数据不一致,下游算子很难解决新旧数据之间的矛盾。对于不确定性算子来说,解决方案通常是杀死下游算子,然后再重跑新数据。
为了避免这种级联故障,最好让算子具有确定性。但需要注意的是,非确定性行为很容易悄悄溜进来:例如,许多编程语言在迭代哈希表的元素时不能对顺序作出保证,许多概率和统计算法显式依赖于使用随机数,以及用到系统时钟或外部数据源,这些都是都不确定性的行为。为了能可靠地从故障中恢复,需要消除这种不确定性因素,例如使用固定的种子生成伪随机数。
通过重算数据来从故障中恢复并不总是正确的答案:如果中间状态数据要比源数据小得多,或者如果计算量非常大,那么将中间数据物化为文件可能要比重新计算廉价的多。
关于物化的讨论
回到 Unix 的类比,我们看到,MapReduce 就像是将每个命令的输出写入临时文件,而数据流引擎看起来更像是 Unix 管道。尤其是 Flink 是基于管道执行的思想而建立的:也就是说,将算子的输出增量地传递给其他算子,不待输入完成便开始处理。
排序算子不可避免地需要消费全部的输入后才能生成任何输出,因为输入中最后一条输入记录可能具有最小的键,因此需要作为第一条记录输出。因此,任何需要排序的算子都需要至少暂时地累积状态。但是工作流的许多其他部分可以以流水线方式执行。
当作业完成时,它的输出需要持续到某个地方,以便用户可以找到并使用它 —— 很可能它会再次写入分布式文件系统。因此,在使用数据流引擎时,HDFS 上的物化数据集通常仍是作业的输入和最终输出。和 MapReduce 一样,输入是不可变的,输出被完全替换。比起 MapReduce 的改进是,你不用再自己去将中间状态写入文件系统了。
图与迭代处理
在 “图数据模型” 中,我们讨论了使用图来建模数据,并使用图查询语言来遍历图中的边与点。第二章 的讨论集中在 OLTP 风格的应用场景:快速执行查询来查找少量符合特定条件的顶点。
批处理上下文中的图也很有趣,其目标是在整个图上执行某种离线处理或分析。这种需求经常出现在机器学习应用(如推荐引擎)或排序系统中。例如,最着名的图形分析算法之一是 PageRank 【69】,它试图根据链接到某个网页的其他网页来估计该网页的流行度。它作为配方的一部分,用于确定网络搜索引擎呈现结果的顺序。
像 Spark、Flink 和 Tez 这样的数据流引擎(请参阅 “物化中间状态”)通常将算子作为 有向无环图(DAG) 的一部分安排在作业中。这与图处理不一样:在数据流引擎中,从一个算子到另一个算子的数据流 被构造成一个图,而数据本身通常由关系型元组构成。在图处理中,数据本身具有图的形式。又一个不幸的命名混乱!
许多图算法是通过一次遍历一条边来表示的,将一个顶点与近邻的顶点连接起来,以传播一些信息,并不断重复,直到满足一些条件为止 —— 例如,直到没有更多的边要跟进,或直到一些指标收敛。我们在 图 2-6 中看到一个例子,它通过重复跟进标明地点归属关系的边,生成了数据库中北美包含的所有地点列表(这种算法被称为 传递闭包,即 transitive closure)。
可以在分布式文件系统中存储图(包含顶点和边的列表的文件),但是这种 “重复至完成” 的想法不能用普通的 MapReduce 来表示,因为它只扫过一趟数据。这种算法因此经常以 迭代 的风格实现:
- 外部调度程序运行批处理来计算算法的一个步骤。
- 当批处理过程完成时,调度器检查它是否完成(基于完成条件 —— 例如,没有更多的边要跟进,或者与上次迭代相比的变化低于某个阈值)。
- 如果尚未完成,则调度程序返回到步骤 1 并运行另一轮批处理。
这种方法是有效的,但是用 MapReduce 实现它往往非常低效,因为 MapReduce 没有考虑算法的迭代性质:它总是读取整个输入数据集并产生一个全新的输出数据集,即使与上次迭代相比,改变的仅仅是图中的一小部分。
Pregel处理模型
针对图批处理的优化 —— 批量同步并行(BSP,Bulk Synchronous Parallel) 计算模型【70】已经开始流行起来。其中,Apache Giraph 【37】,Spark 的 GraphX API 和 Flink 的 Gelly API 【71】实现了它。它也被称为 Pregel 模型,因为 Google 的 Pregel 论文推广了这种处理图的方法【72】。
回想一下在 MapReduce 中,Mapper 在概念上向 Reducer 的特定调用 “发送消息”,因为框架将所有具有相同键的 Mapper 输出集中在一起。 Pregel 背后有一个类似的想法:一个顶点可以向另一个顶点 “发送消息”,通常这些消息是沿着图的边发送的。
在每次迭代中,为每个顶点调用一个函数,将所有发送给它的消息传递给它 —— 就像调用 Reducer 一样。与 MapReduce 的不同之处在于,在 Pregel 模型中,顶点在一次迭代到下一次迭代的过程中会记住它的状态,所以这个函数只需要处理新的传入消息。如果图的某个部分没有被发送消息,那里就不需要做任何工作。
这与 Actor 模型有些相似(请参阅 “分布式的 Actor 框架”),除了顶点状态和顶点之间的消息具有容错性和持久性,且通信以固定的回合进行:在每次迭代中,框架递送上次迭代中发送的所有消息。Actor 通常没有这样的时序保证。
容错
顶点只能通过消息传递进行通信(而不是直接相互查询)的事实有助于提高 Pregel 作业的性能,因为消息可以成批处理,且等待通信的次数也减少了。唯一的等待是在迭代之间:由于 Pregel 模型保证所有在一轮迭代中发送的消息都在下轮迭代中送达,所以在下一轮迭代开始前,先前的迭代必须完全完成,而所有的消息必须在网络上完成复制。
即使底层网络可能丢失、重复或任意延迟消息(请参阅 “不可靠的网络”),Pregel 的实现能保证在后续迭代中消息在其目标顶点恰好处理一次。像 MapReduce 一样,框架能从故障中透明地恢复,以简化在 Pregel 上实现算法的编程模型。
这种容错是通过在迭代结束时,定期存档所有顶点的状态来实现的,即将其全部状态写入持久化存储。如果某个节点发生故障并且其内存中的状态丢失,则最简单的解决方法是将整个图计算回滚到上一个存档点,然后重启计算。如果算法是确定性的,且消息记录在日志中,那么也可以选择性地只恢复丢失的分区(就像之前讨论过的数据流引擎)【72】。
并行执行
顶点不需要知道它在哪台物理机器上执行;当它向其他顶点发送消息时,它只是简单地将消息发往某个顶点 ID。图的分区取决于框架 —— 即,确定哪个顶点运行在哪台机器上,以及如何通过网络路由消息,以便它们到达正确的地方。
由于编程模型一次仅处理一个顶点(有时称为 “像顶点一样思考”),所以框架可以以任意方式对图分区。理想情况下如果顶点需要进行大量的通信,那么它们最好能被分区到同一台机器上。然而找到这样一种优化的分区方法是很困难的 —— 在实践中,图经常按照任意分配的顶点 ID 分区,而不会尝试将相关的顶点分组在一起。
因此,图算法通常会有很多跨机器通信的额外开销,而中间状态(节点之间发送的消息)往往比原始图大。通过网络发送消息的开销会显著拖慢分布式图算法的速度。
出于这个原因,如果你的图可以放入一台计算机的内存中,那么单机(甚至可能是单线程)算法很可能会超越分布式批处理【73,74】。图比内存大也没关系,只要能放入单台计算机的磁盘,使用 GraphChi 等框架进行单机处理是就一个可行的选择【75】。如果图太大,不适合单机处理,那么像 Pregel 这样的分布式方法是不可避免的。高效的并行图算法是一个进行中的研究领域【76】。
高级API和语言
自 MapReduce 开始流行的这几年以来,分布式批处理的执行引擎已经很成熟了。到目前为止,基础设施已经足够强大,能够存储和处理超过 10,000 台机器集群上的数 PB 的数据。由于在这种规模下物理执行批处理的问题已经被认为或多或少解决了,所以关注点已经转向其他领域:改进编程模型,提高处理效率,扩大这些技术可以解决的问题集。
如前所述,Hive、Pig、Cascading 和 Crunch 等高级语言和 API 变得越来越流行,因为手写 MapReduce 作业实在是个苦力活。随着 Tez 的出现,这些高级语言还有一个额外好处,可以迁移到新的数据流执行引擎,而无需重写作业代码。Spark 和 Flink 也有它们自己的高级数据流 API,通常是从 FlumeJava 中获取的灵感【34】。
这些数据流 API 通常使用关系型构建块来表达一个计算:按某个字段连接数据集;按键对元组做分组;按某些条件过滤;并通过计数求和或其他函数来聚合元组。在内部,这些操作是使用本章前面讨论过的各种连接和分组算法来实现的。
除了少写代码的明显优势之外,这些高级接口还支持交互式用法,在这种交互式使用中,你可以在 Shell 中增量式编写分析代码,频繁运行来观察它做了什么。这种开发风格在探索数据集和试验处理方法时非常有用。这也让人联想到 Unix 哲学,我们在 “Unix 哲学” 中讨论过这个问题。
此外,这些高级接口不仅提高了人类的工作效率,也提高了机器层面的作业执行效率。
向声明式查询语言的转变
与硬写执行连接的代码相比,指定连接关系算子的优点是,框架可以分析连接输入的属性,并自动决定哪种上述连接算法最适合当前任务。 Hive、Spark 和 Flink 都有基于代价的查询优化器可以做到这一点,甚至可以改变连接顺序,最小化中间状态的数量【66,77,78,79】。
连接算法的选择可以对批处理作业的性能产生巨大影响,而无需理解和记住本章中讨论的各种连接算法。如果连接是以 声明式(declarative) 的方式指定的,那这就这是可行的:应用只是简单地说明哪些连接是必需的,查询优化器决定如何最好地执行连接。我们以前在 “数据查询语言” 中见过这个想法。
但 MapReduce 及其数据流后继者在其他方面,与 SQL 的完全声明式查询模型有很大区别。 MapReduce 是围绕着回调函数的概念建立的:对于每条记录或者一组记录,调用一个用户定义的函数(Mapper 或 Reducer),并且该函数可以自由地调用任意代码来决定输出什么。这种方法的优点是可以基于大量已有库的生态系统创作:解析、自然语言分析、图像分析以及运行数值或统计算法等。
自由运行任意代码,长期以来都是传统 MapReduce 批处理系统与 MPP 数据库的区别所在(请参阅 “Hadoop 与分布式数据库的对比” 一节)。虽然数据库具有编写用户定义函数的功能,但是它们通常使用起来很麻烦,而且与大多数编程语言中广泛使用的程序包管理器和依赖管理系统兼容不佳(例如 Java 的 Maven、Javascript 的 npm 以及 Ruby 的 gems)。
然而数据流引擎已经发现,支持除连接之外的更多 声明式特性 还有其他的优势。例如,如果一个回调函数只包含一个简单的过滤条件,或者只是从一条记录中选择了一些字段,那么在为每条记录调用函数时会有相当大的额外 CPU 开销。如果以声明方式表示这些简单的过滤和映射操作,那么查询优化器可以利用列式存储布局(请参阅 “列式存储”),只从磁盘读取所需的列。 Hive、Spark DataFrames 和 Impala 还使用了向量化执行(请参阅 “内存带宽和矢量化处理”):在对 CPU 缓存友好的内部循环中迭代数据,避免函数调用。Spark 生成 JVM 字节码【79】,Impala 使用 LLVM 为这些内部循环生成本机代码【41】。
通过在高级 API 中引入声明式的部分,并使查询优化器可以在执行期间利用这些来做优化,批处理框架看起来越来越像 MPP 数据库了(并且能实现可与之媲美的性能)。同时,通过拥有运行任意代码和以任意格式读取数据的可扩展性,它们保持了灵活性的优势。
专业化的不同领域
尽管能够运行任意代码的可扩展性是很有用的,但是也有很多常见的例子,不断重复着标准的处理模式。因而这些模式值得拥有自己的可重用通用构建模块实现。传统上,MPP 数据库满足了商业智能分析和业务报表的需求,但这只是许多使用批处理的领域之一。
另一个越来越重要的领域是统计和数值算法,它们是机器学习应用所需要的(例如分类器和推荐系统)。可重用的实现正在出现:例如,Mahout 在 MapReduce、Spark 和 Flink 之上实现了用于机器学习的各种算法,而 MADlib 在关系型 MPP 数据库(Apache HAWQ)中实现了类似的功能【54】。
空间算法也是有用的,例如 k 近邻搜索(k-nearest neighbors, kNN)【80】,它在一些多维空间中搜索与给定项最近的项目 —— 这是一种相似性搜索。近似搜索对于基因组分析算法也很重要,它们需要找到相似但不相同的字符串【81】。
批处理引擎正被用于分布式执行日益广泛的各领域算法。随着批处理系统获得各种内置功能以及高级声明式算子,且随着 MPP 数据库变得更加灵活和易于编程,两者开始看起来相似了:最终,它们都只是存储和处理数据的系统。
本章小结
在本章中,我们探索了批处理的主题。我们首先看到了诸如 awk、grep 和 sort 之类的 Unix 工具,然后我们看到了这些工具的设计理念是如何应用到 MapReduce 和更近的数据流引擎中的。一些设计原则包括:输入是不可变的,输出是为了作为另一个(仍未知的)程序的输入,而复杂的问题是通过编写 “做好一件事” 的小工具来解决的。
在 Unix 世界中,允许程序与程序组合的统一接口是文件与管道;在 MapReduce 中,该接口是一个分布式文件系统。我们看到数据流引擎添加了自己的管道式数据传输机制,以避免将中间状态物化至分布式文件系统,但作业的初始输入和最终输出通常仍是 HDFS。
分布式批处理框架需要解决的两个主要问题是:
分区
在 MapReduce 中,Mapper 根据输入文件块进行分区。Mapper 的输出被重新分区、排序并合并到可配置数量的 Reducer 分区中。这一过程的目的是把所有的 相关 数据(例如带有相同键的所有记录)都放在同一个地方。
后 MapReduce 时代的数据流引擎若非必要会尽量避免排序,但它们也采取了大致类似的分区方法。
容错
MapReduce 经常写入磁盘,这使得从单个失败的任务恢复很轻松,无需重新启动整个作业,但在无故障的情况下减慢了执行速度。数据流引擎更多地将中间状态保存在内存中,更少地物化中间状态,这意味着如果节点发生故障,则需要重算更多的数据。确定性算子减少了需要重算的数据量。
我们讨论了几种 MapReduce 的连接算法,其中大多数也在 MPP 数据库和数据流引擎内部使用。它们也很好地演示了分区算法是如何工作的:
排序合并连接
每个参与连接的输入都通过一个提取连接键的 Mapper。通过分区、排序和合并,具有相同键的所有记录最终都会进入相同的 Reducer 调用。这个函数能输出连接好的记录。
广播散列连接
两个连接输入之一很小,所以它并没有分区,而且能被完全加载进一个哈希表中。因此,你可以为连接输入大端的每个分区启动一个 Mapper,将输入小端的散列表加载到每个 Mapper 中,然后扫描大端,一次一条记录,并为每条记录查询散列表。
分区散列连接
如果两个连接输入以相同的方式分区(使用相同的键,相同的散列函数和相同数量的分区),则可以独立地对每个分区应用散列表方法。
分布式批处理引擎有一个刻意限制的编程模型:回调函数(比如 Mapper 和 Reducer)被假定是无状态的,而且除了指定的输出外,必须没有任何外部可见的副作用。这一限制允许框架在其抽象下隐藏一些困难的分布式系统问题:当遇到崩溃和网络问题时,任务可以安全地重试,任何失败任务的输出都被丢弃。如果某个分区的多个任务成功,则其中只有一个能使其输出实际可见。
得益于这个框架,你在批处理作业中的代码无需操心实现容错机制:框架可以保证作业的最终输出与没有发生错误的情况相同,虽然实际上也许不得不重试各种任务。比起在线服务一边处理用户请求一边将写入数据库作为处理请求的副作用,批处理提供的这种可靠性语义要强得多。
批处理作业的显著特点是,它读取一些输入数据并产生一些输出数据,但不修改输入 —— 换句话说,输出是从输入衍生出的。最关键的是,输入数据是 有界的(bounded):它有一个已知的,固定的大小(例如,它包含一些时间点的日志文件或数据库内容的快照)。因为它是有界的,一个作业知道自己什么时候完成了整个输入的读取,所以一个工作在做完后,最终总是会完成的。
在下一章中,我们将转向流处理,其中的输入是 无界的(unbounded) —— 也就是说,你还有活儿要干,然而它的输入是永无止境的数据流。在这种情况下,作业永无完成之日。因为在任何时候都可能有更多的工作涌入。我们将看到,在某些方面上,流处理和批处理是相似的。但是关于无尽数据流的假设也对我们构建系统的方式产生了很多改变。
参考文献
- Jeffrey Dean and Sanjay Ghemawat: “MapReduce: Simplified Data Processing on Large Clusters,” at 6th USENIX Symposium on Operating System Design and Implementation (OSDI), December 2004.
- Joel Spolsky: “The Perils of JavaSchools,” joelonsoftware.com, December 25, 2005.
- Shivnath Babu and Herodotos Herodotou: “Massively Parallel Databases and MapReduce Systems,” Foundations and Trends in Databases, volume 5, number 1, pages 1–104, November 2013. doi:10.1561/1900000036
- David J. DeWitt and Michael Stonebraker: “MapReduce: A Major Step Backwards,” originally published at databasecolumn.vertica.com, January 17, 2008.
- Henry Robinson: “The Elephant Was a Trojan Horse: On the Death of Map-Reduce at Google,” the-paper-trail.org, June 25, 2014.
- “The Hollerith Machine,” United States Census Bureau, census.gov.
- “IBM 82, 83, and 84 Sorters Reference Manual,” Edition A24-1034-1, International Business Machines Corporation, July 1962.
- Adam Drake: “Command-Line Tools Can Be 235x Faster than Your Hadoop Cluster,” aadrake.com, January 25, 2014.
- “GNU Coreutils 8.23 Documentation,” Free Software Foundation, Inc., 2014.
- Martin Kleppmann: “Kafka, Samza, and the Unix Philosophy of Distributed Data,” martin.kleppmann.com, August 5, 2015.
- Doug McIlroy:Internal Bell Labs memo, October 1964. Cited in: Dennis M. Richie: “Advice from Doug McIlroy,” cm.bell-labs.com.
- M. D. McIlroy, E. N. Pinson, and B. A. Tague: “UNIX Time-Sharing System: Foreword,” The Bell System Technical Journal, volume 57, number 6, pages 1899–1904, July 1978.
- Eric S. Raymond: The Art of UNIX Programming. Addison-Wesley, 2003. ISBN: 978-0-13-142901-7
- Ronald Duncan: “Text File Formats – ASCII Delimited Text – Not CSV or TAB Delimited Text,” ronaldduncan.wordpress.com, October 31, 2009.
- Alan Kay: “Is ‘Software Engineering’ an Oxymoron?,” tinlizzie.org.
- Martin Fowler: “InversionOfControl,” martinfowler.com, June 26, 2005.
- Daniel J. Bernstein: “Two File Descriptors for Sockets,” cr.yp.to.
- Rob Pike and Dennis M. Ritchie: “The Styx Architecture for Distributed Systems,” Bell Labs Technical Journal, volume 4, number 2, pages 146–152, April 1999.
- Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung: “The Google File System,” at 19th ACM Symposium on Operating Systems Principles (SOSP), October 2003. doi:10.1145/945445.945450
- Michael Ovsiannikov, Silvius Rus, Damian Reeves, et al.: “The Quantcast File System,” Proceedings of the VLDB Endowment, volume 6, number 11, pages 1092–1101, August 2013. doi:10.14778/2536222.2536234
- “OpenStack Swift 2.6.1 Developer Documentation,” OpenStack Foundation, docs.openstack.org, March 2016.
- Zhe Zhang, Andrew Wang, Kai Zheng, et al.: “Introduction to HDFS Erasure Coding in Apache Hadoop,” blog.cloudera.com, September 23, 2015.
- Peter Cnudde: “Hadoop Turns 10,” yahoohadoop.tumblr.com, February 5, 2016.
- Eric Baldeschwieler: “Thinking About the HDFS vs. Other Storage Technologies,” hortonworks.com, July 25, 2012.
- Brendan Gregg: “Manta: Unix Meets Map Reduce,” dtrace.org, June 25, 2013.
- Tom White: Hadoop: The Definitive Guide, 4th edition. O’Reilly Media, 2015. ISBN: 978-1-491-90163-2
- Jim N. Gray: “Distributed Computing Economics,” Microsoft Research Tech Report MSR-TR-2003-24, March 2003.
- Márton Trencséni: “Luigi vs Airflow vs Pinball,” bytepawn.com, February 6, 2016.
- Roshan Sumbaly, Jay Kreps, and Sam Shah: “The ‘Big Data’ Ecosystem at LinkedIn,” at ACM International Conference on Management of Data (SIGMOD), July 2013. doi:10.1145/2463676.2463707
- Alan F. Gates, Olga Natkovich, Shubham Chopra, et al.: “Building a High-Level Dataflow System on Top of Map-Reduce: The Pig Experience,” at 35th International Conference on Very Large Data Bases (VLDB), August 2009.
- Ashish Thusoo, Joydeep Sen Sarma, Namit Jain, et al.: “Hive – A Petabyte Scale Data Warehouse Using Hadoop,” at 26th IEEE International Conference on Data Engineering (ICDE), March 2010. doi:10.1109/ICDE.2010.5447738
- “Cascading 3.0 User Guide,” Concurrent, Inc., docs.cascading.org, January 2016.
- “Apache Crunch User Guide,” Apache Software Foundation, crunch.apache.org.
- Craig Chambers, Ashish Raniwala, Frances Perry, et al.: “FlumeJava: Easy, Efficient Data-Parallel Pipelines,” at 31st ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), June 2010. doi:10.1145/1806596.1806638
- Jay Kreps: “Why Local State is a Fundamental Primitive in Stream Processing,” oreilly.com, July 31, 2014.
- Martin Kleppmann: “Rethinking Caching in Web Apps,” martin.kleppmann.com, October 1, 2012.
- Mark Grover, Ted Malaska, Jonathan Seidman, and Gwen Shapira: Hadoop Application Architectures. O’Reilly Media, 2015. ISBN: 978-1-491-90004-8
- Philippe Ajoux, Nathan Bronson, Sanjeev Kumar, et al.: “Challenges to Adopting Stronger Consistency at Scale,” at 15th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2015.
- Sriranjan Manjunath: “Skewed Join,” wiki.apache.org, 2009.
- David J. DeWitt, Jeffrey F. Naughton, Donovan A.Schneider, and S. Seshadri: “Practical Skew Handling in Parallel Joins,” at 18th International Conference on Very Large Data Bases (VLDB), August 1992.
- Marcel Kornacker, Alexander Behm, Victor Bittorf, et al.: “Impala: A Modern, Open-Source SQL Engine for Hadoop,” at 7th Biennial Conference on Innovative Data Systems Research (CIDR), January 2015.
- Matthieu Monsch: “Open-Sourcing PalDB, a Lightweight Companion for Storing Side Data,” engineering.linkedin.com, October 26, 2015.
- Daniel Peng and Frank Dabek: “Large-Scale Incremental Processing Using Distributed Transactions and Notifications,” at 9th USENIX conference on Operating Systems Design and Implementation (OSDI), October 2010.
- ““Cloudera Search User Guide,” Cloudera, Inc., September 2015.
- Lili Wu, Sam Shah, Sean Choi, et al.: “The Browsemaps: Collaborative Filtering at LinkedIn,” at 6th Workshop on Recommender Systems and the Social Web (RSWeb), October 2014.
- Roshan Sumbaly, Jay Kreps, Lei Gao, et al.: “Serving Large-Scale Batch Computed Data with Project Voldemort,” at 10th USENIX Conference on File and Storage Technologies (FAST), February 2012.
- Varun Sharma: “Open-Sourcing Terrapin: A Serving System for Batch Generated Data,” engineering.pinterest.com, September 14, 2015.
- Nathan Marz: “ElephantDB,” slideshare.net, May 30, 2011.
- Jean-Daniel (JD) Cryans: “How-to: Use HBase Bulk Loading, and Why,” blog.cloudera.com, September 27, 2013.
- Nathan Marz: “How to Beat the CAP Theorem,” nathanmarz.com, October 13, 2011.
- Molly Bartlett Dishman and Martin Fowler: “Agile Architecture,” at O’Reilly Software Architecture Conference, March 2015.
- David J. DeWitt and Jim N. Gray: “Parallel Database Systems: The Future of High Performance Database Systems,” Communications of the ACM, volume 35, number 6, pages 85–98, June 1992. doi:10.1145/129888.129894
- Jay Kreps: “But the multi-tenancy thing is actually really really hard,” tweetstorm, twitter.com, October 31, 2014.
- Jeffrey Cohen, Brian Dolan, Mark Dunlap, et al.: “MAD Skills: New Analysis Practices for Big Data,” Proceedings of the VLDB Endowment, volume 2, number 2, pages 1481–1492, August 2009. doi:10.14778/1687553.1687576
- Ignacio Terrizzano, Peter Schwarz, Mary Roth, and John E. Colino: “Data Wrangling: The Challenging Journey from the Wild to the Lake,” at 7th Biennial Conference on Innovative Data Systems Research (CIDR), January 2015.
- Paige Roberts: “To Schema on Read or to Schema on Write, That Is the Hadoop Data Lake Question,” adaptivesystemsinc.com, July 2, 2015.
- Bobby Johnson and Joseph Adler: “The Sushi Principle: Raw Data Is Better,” at Strata+Hadoop World, February 2015.
- Vinod Kumar Vavilapalli, Arun C. Murthy, Chris Douglas, et al.: “Apache Hadoop YARN: Yet Another Resource Negotiator,” at 4th ACM Symposium on Cloud Computing (SoCC), October 2013. doi:10.1145/2523616.2523633
- Abhishek Verma, Luis Pedrosa, Madhukar Korupolu, et al.: “Large-Scale Cluster Management at Google with Borg,” at 10th European Conference on Computer Systems (EuroSys), April 2015. doi:10.1145/2741948.2741964
- Malte Schwarzkopf: “The Evolution of Cluster Scheduler Architectures,” firmament.io, March 9, 2016.
- Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, et al.: “Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing,” at 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI), April 2012.
- Holden Karau, Andy Konwinski, Patrick Wendell, and Matei Zaharia: Learning Spark. O’Reilly Media, 2015. ISBN: 978-1-449-35904-1
- Bikas Saha and Hitesh Shah: “Apache Tez: Accelerating Hadoop Query Processing,” at Hadoop Summit, June 2014.
- Bikas Saha, Hitesh Shah, Siddharth Seth, et al.: “Apache Tez: A Unifying Framework for Modeling and Building Data Processing Applications,” at ACM International Conference on Management of Data (SIGMOD), June 2015. doi:10.1145/2723372.2742790
- Kostas Tzoumas: “Apache Flink: API, Runtime, and Project Roadmap,” slideshare.net, January 14, 2015.
- Alexander Alexandrov, Rico Bergmann, Stephan Ewen, et al.: “The Stratosphere Platform for Big Data Analytics,” The VLDB Journal, volume 23, number 6, pages 939–964, May 2014. doi:10.1007/s00778-014-0357-y
- Michael Isard, Mihai Budiu, Yuan Yu, et al.: “Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks,” at European Conference on Computer Systems (EuroSys), March 2007. doi:10.1145/1272996.1273005
- Daniel Warneke and Odej Kao: “Nephele: Efficient Parallel Data Processing in the Cloud,” at 2nd Workshop on Many-Task Computing on Grids and Supercomputers (MTAGS), November 2009. doi:10.1145/1646468.1646476
- Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd: “The PageRank”
- Leslie G. Valiant: “A Bridging Model for Parallel Computation,” Communications of the ACM, volume 33, number 8, pages 103–111, August 1990. doi:10.1145/79173.79181
- Stephan Ewen, Kostas Tzoumas, Moritz Kaufmann, and Volker Markl: “Spinning Fast Iterative Data Flows,” Proceedings of the VLDB Endowment, volume 5, number 11, pages 1268-1279, July 2012. doi:10.14778/2350229.2350245
- Grzegorz Malewicz, Matthew H.Austern, Aart J. C. Bik, et al.: “Pregel: A System for Large-Scale Graph Processing,” at ACM International Conference on Management of Data (SIGMOD), June 2010. doi:10.1145/1807167.1807184
- Frank McSherry, Michael Isard, and Derek G. Murray: “Scalability! But at What COST?,” at 15th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2015.
- Ionel Gog, Malte Schwarzkopf, Natacha Crooks, et al.: “Musketeer: All for One, One for All in Data Processing Systems,” at 10th European Conference on Computer Systems (EuroSys), April 2015. doi:10.1145/2741948.2741968
- Aapo Kyrola, Guy Blelloch, and Carlos Guestrin: “GraphChi: Large-Scale Graph Computation on Just a PC,” at 10th USENIX Symposium on Operating Systems Design and Implementation (OSDI), October 2012.
- Andrew Lenharth, Donald Nguyen, and Keshav Pingali: “Parallel Graph Analytics,” Communications of the ACM, volume 59, number 5, pages 78–87, May doi:10.1145/2901919
- Fabian Hüske: “Peeking into Apache Flink’s Engine Room,” flink.apache.org, March 13, 2015.
- Mostafa Mokhtar: “Hive 0.14 Cost Based Optimizer (CBO) Technical Overview,” hortonworks.com, March 2, 2015.
- Michael Armbrust, Reynold S Xin, Cheng Lian, et al.: “Spark SQL: Relational Data Processing in Spark,” at ACM International Conference on Management of Data (SIGMOD), June 2015. doi:10.1145/2723372.2742797
- Daniel Blazevski: “Planting Quadtrees for Apache Flink,” insightdataengineering.com, March 25, 2016.
- Tom White: “Genome Analysis Toolkit: Now Using Apache Spark for Data Processing,” blog.cloudera.com, April 6, 2016.