Kafka 系列(二):Producer 原理篇
Kafka 系列文章列表
Kafka 版本:2021-11 trunk 分支(当前最新版本3.0.0)
一个正常的生产者逻辑需要具备以下几个步骤:
- 配置生产者客户端参数以及创建相应的生产者实例
- 构建待发送的消息
- 发送消息
- 关闭生产者实例
序列化器
生产者在发送消息时,需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给kafka,同样的消费者需要用反序列化器(Deserializer)把从Kafka中收到的字节数组转换成相应的对象。
生产者使用的序列化器和消费者使用的反序列化器需要一一对应。
kafka 客户端提供了多种序列化器,同时也支持自定义实现序列化器(可以选择使用如 Avro、JSON、Thrift、ProtoBuf、Protostuff等通用的序列化工具来实现)。
分区器
消息在通过 send() 方法发往 broke 的过程中,有可能需要经过拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)的一些列作用之后才能被真正的发往kafka。拦截器一般不是必须的,而序列化器是必需的。
消息经过序列化器之后就需要确定他发往的分区,如果消息 ProducerRecord 中指定了具体的 partition 字段,那么就不需要分区器的作用,因为partition 就代表了要发往的分区号。
如果消息没有指定分区号,那么就需要依赖分区器,根据 key 这个字段来计算 partition 的值。分区器的作用就是为消息分配分区。
kafka 中提供的默认分区器的计算逻辑是:
- 如果 key 不为 null,则对 key 进行 哈希 (采用 MurmurHash2 算法),最终根据到的哈希值计算分区号,拥有相同key的消息会被发送到同一个分区
- 如果 key 为 null,消息将会以轮训的方式发往主题内的各个可用分区
在不改变主题分区的数量下,key 和分区之间的映射关系可以保持不变,一旦主题的分区数量发生变化(增加分区),那么映射关系就很难保证了。
除了 kafka 默认提供的分区器外,还可以使用自定义的分区器,只需要同 DefaultPartitioner 一样实现 Partitioner 接口即可。
实现自定义分区器之后,需要通过配置参数显示指定自定义分区器。
拦截器
kafka 一共有两种拦截器:生产者拦截器和消费者拦截器。
生产者拦截器既可以在 消息发送前 做一些准备工作,比如按照某个规则过滤不符合条件的消息、修改消息的内容等,也可以在 发送回调逻辑前 做一些定制化的需求,比如统计类的工作。
实现方式:实现 ProducerInterceptor 接口,该接口提供如下三个方法
- onSend
- onAcknowledgement
- close
KafkaProducer 再将消息序列化和计算分区之前会调用生产者拦截器的 onSend() 方法来对消息进行相应的定制化操作。(一般来说最好不要修改 ProducerRecord 的 topic key partition 等信息,不然有可能影响分区的计算以及broker端日志的压缩功能)
KafkaProducer 会在消息被应答之前和消息发送失败时调用生产者拦截器的 onAcknowledgement() 方法,优先于用户设定的 Callback 之前执行。这个方法运行在 Producer 的 IO 线程中,所以逻辑越简单越好,否则会影响消息发送的速度。
close() 方法主要用于在关闭拦截器时,执行一些资源的清理工作。
这三个方法中抛出的异常会被捕获并记录到日志中,并不会向上传递。
整体架构
kafka 中同个生产者客户端由两个线程协调运行,分别为:主线程和 Sender 线程(发送线程)。
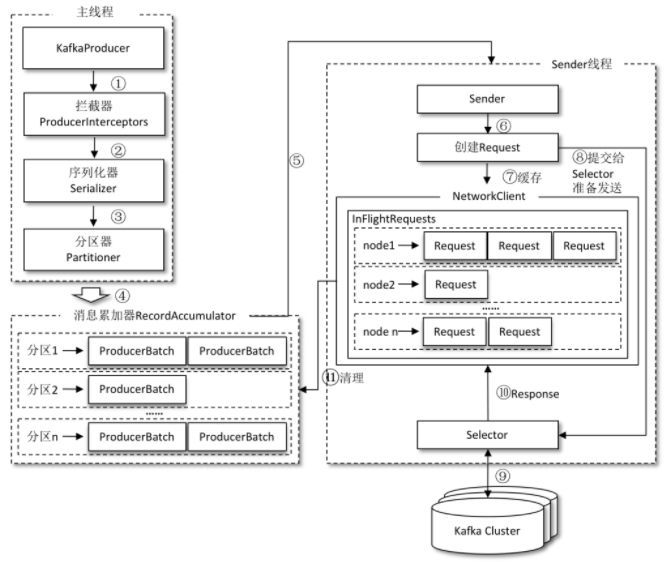
在主线程中由 KafkaProducer 创建消息,然后通过 可能的 拦截器、序列化器、分区器的作用之后,缓存到消息累加器 RecordAccumulator 中。Sender 线程负责从消息累加器中获取消息并将其发送到 kafka 中。
消息累加器 主要用来缓存消息以便 Sender 线程可以批量发送,进而减少网络传输的资源消耗以提升性能。消息累加器缓存的大小可以通过配置 buffer.memory 指定(默认为 33554432 B – 32MB)。如果发送速度超过了发送到服务器的速度,则会导致生产者空间不足,这时候 send() 方法调用要么被阻塞,要么抛出异常,这取决于 max.block.ms 的配置,默认为 60000 – 60s。
主线程中发送过来的消息都会被追加到 RecordAccumulator 的某个双端队列(Deque)中,在 RecordAccumulator 的内部为每个分区都维护了一个双端队列,队列中的内容就是ProducerBatch ,即 Deque<ProducerBatch> 。消息写入缓存时,追加到双端队列的尾部;
Sender 读取消息时,从双端队列的头部读取。注意ProducerBatch不是ProducerRecord,ProducerBatch中可以包含一至多个ProducerRecord。通俗地说,ProducerRecord 是生产者中创建的消息,而ProducerBatch是指一个消息批次,ProducerRecord会被包含在ProducerBatch中,这样可以使字节的使用更加紧凑。与此同时,将较小的ProducerRecord拼凑成一个较大的ProducerBatch,也可以减少网络请求的次数以提升整体的吞吐量。如果生产者客户端需要向很多分区发送消息,则可以将buffer.memory参数适当调大以增加整体的吞吐量。
消息在网络上都是以字节(Byte)的形式传输的,在发送之前需要创建一块内存区域来保存对应的消息。在Kafka生产者客户端中,通过java.io.ByteBuffer实现消息内存的创建和释放。不过频繁的创建和释放是比较耗费资源的,在RecordAccumulator的内部还有一个BufferPool,它主要用来实现ByteBuffer的复用,以实现缓存的高效利用。不过BufferPool只针对特定大小的ByteBuffer进行管理,而其他大小的ByteBuffer不会缓存进BufferPool中,这个特定的大小由batch.size参数来指定,默认值为16384B,即16KB。我们可以适当地调大batch.size参数以便多缓存一些消息。
ProducerBatch的大小和batch.size参数也有着密切的关系。当一条消息(ProducerRecord)流入RecordAccumulator时,会先寻找与消息分区所对应的双端队列(如果没有则新建),再从这个双端队列的尾部获取一个 ProducerBatch(如果没有则新建),查看 ProducerBatch 中是否还可以写入这个ProducerRecord,如果可以则写入,如果不可以则需要创建一个新的ProducerBatch。在新建ProducerBatch时评估这条消息的大小是否超过batch.size参数的大小,如果不超过,那么就以 batch.size 参数的大小来创建ProducerBatch,这样在使用完这段内存区域之后,可以通过BufferPool 的管理来进行复用;如果超过,那么就以评估的大小来创建ProducerBatch,这段内存区域不会被复用。
Sender 从 RecordAccumulator 中获取缓存的消息之后,会进一步将原本 <分区,Deque<ProducerBatch>> 的保存形式转变成 <Node,List<ProducerBatch>> 的形式,其中Node表示Kafka集群的broker节点。对于网络连接来说,生产者客户端是与具体的broker节点建立的连接,也就是向具体的broker 节点发送消息,而并不关心消息属于哪一个分区;而对于 KafkaProducer的应用逻辑而言,我们只关注向哪个分区中发送哪些消息,所以在这里需要做一个应用逻辑层面到网络I/O层面的转换。
在转换成 <Node,List<ProducerBatch>> 的形式之后,Sender 还会进一步封装成 <Node,Request> 的形式,这样就可以将Request请求发往各个Node了,这里的Request是指Kafka的各种协议请求,对于消息发送而言就是指具体的ProduceRequest
请求在从Sender线程发往Kafka之前还会保存到InFlightRequests中,InFlightRequests保存对象的具体形式为 Map<NodeId,Deque<Request>> ,它的主要作用是缓存了已经发出去但还没有收到响应的请求(NodeId 是一个String 类型,表示节点的 id 编号)。与此同时,InFlightRequests还提供了许多管理类的方法,并且通过配置参数还可以限制每个连接(也就是客户端与Node之间的连接)最多缓存的请求数。这个配置参数为max.in.flight.requests.per.connection,默认值为 5,即每个连接最多只能缓存 5个未响应的请求,超过该数值之后就不能再向这个连接发送更多的请求了,除非有缓存的请求收到了响应(Response)。通过比较 Deque<Request> 的size与这个参数的大小来判断对应的Node中是否已经堆积了很多未响应的消息,如果真是如此,那么说明这个 Node 节点负载较大或网络连接有问题,再继续向其发送请求会增大请求超时的可能。
leastLoadedNode
InFlightRequests还可以获得leastLoadedNode,即所有Node中负载最小的那一个。这里的负载最小是通过每个Node在InFlightRequests中还未确认的请求决定的,未确认的请求越多则认为负载越大。
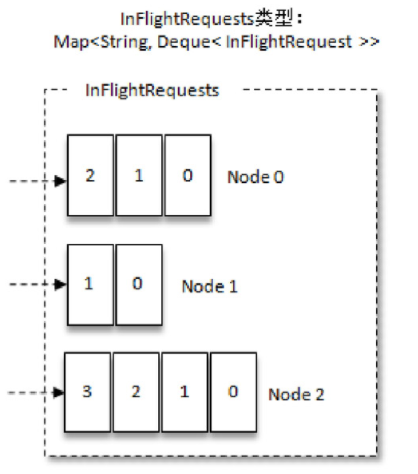
图中展示了三个节点Node0、Node1和Node2,很明显Node1的负载最小。也就是说,Node1为当前的leastLoadedNode。选择leastLoadedNode发送请求可以使它能够尽快发出,避免因网络拥塞等异常而影响整体的进度。leastLoadedNode的概念可以用于多个应用场合,比如元数据请求、消费者组播协议的交互。
当客户端中没有需要使用的元数据信息时,比如没有指定的主题信息,或者超过metadata.max.age.ms 时间没有更新元数据都会引起元数据的更新操作。客户端参数metadata.max.age.ms的默认值为300000,即5分钟。元数据的更新操作是在客户端内部进行的,对客户端的外部使用者不可见。当需要更新元数据时,会先挑选出leastLoadedNode,然后向这个Node发送MetadataRequest请求来获取具体的元数据信息。这个更新操作是由Sender线程发起的,在创建完MetadataRequest之后同样会存入InFlightRequests,之后的步骤就和发送消息时的类似。元数据虽然由Sender线程负责更新,但是主线程也需要读取这些信息,这里的数据同步通过synchronized和final关键字来保障。