Kafka有哪几处地方有分区分配的概念?
在 kafka 中,分区分配是一个很重要的概念,它会影响Kafka整体的性能均衡。kafka 中一共有三处地方涉及此概念,分别是:
- 生产者发送消息
- 消费者消费消息
- 创建主题。
虽然这三处的对应操作都可以被称之为 分区分配,但是其实质上所包含的内容却并不相同。
生产者的分区分配
用户在使用 kafka 客户端发送消息时,调用 send 方法发送消息之后,消息就自然而然的发送到了 broker 中。
其实这一过程需要经过拦截器、序列化器、分区器等一系列作用之后才能被真正发往 broker。消息在发往 broker 之前需要确认它需要发送到的分区,如果 ProducerRecord 中指定了 partition 字段,那就不需要分区器的作用,因为 partition 就代表的是所要发往的分区号。如果消息ProducerRecord中没有指定partition字段,那么就需要依赖分区器,根据key这个字段来计算partition的值。分区器的作用就是为消息分配分区。
Kafka中提供的默认分区器是DefaultPartitioner,它实现了Partitioner接口(用户可以实现这个接口来自定义分区器),其中的partition方法就是用来实现具体的分区分配逻辑:
1 | public int partition(String topic, Object key, byte[] keyBytes, |
默认情况下,如果消息的key不为null,那么默认的分区器会对key进行哈希(采用MurmurHash2算法,具备高运算性能及低碰撞率),最终根据得到的哈希值来计算分区号,拥有相同key的消息会被写入同一个分区。如果key为null,那么消息将会以轮询的方式发往 topic 的各个可用分区。
注意:如果key不为null,那么计算得到的分区号会是所有分区中的任意一个;如果key为null并且有可用分区,那么计算得到的分区号仅为可用分区中的任意一个,注意两者之间的差别。
消费者的分区分配
在Kafka的默认规则中,每一个分区只能被同一个消费组中的一个消费者消费。消费者的分区分配是指为消费组中的消费者分配所订阅主题中的分区。
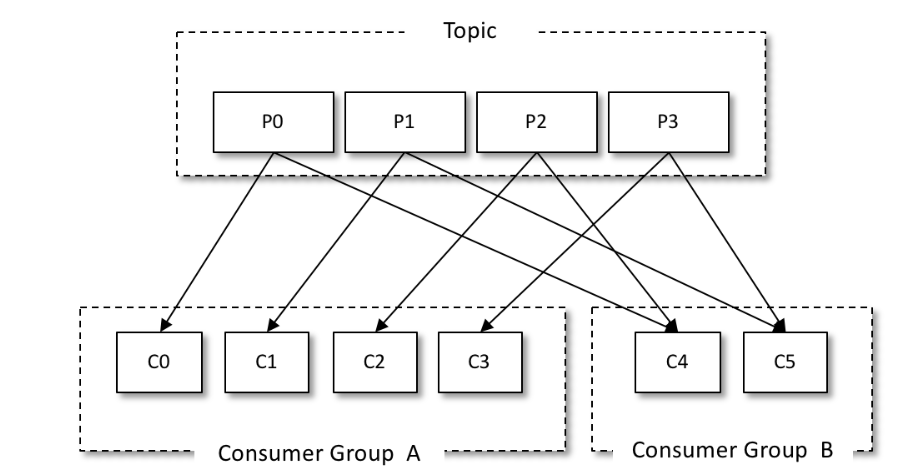
如图所示,某个主题中共有4个分区(Partition):P0、P1、P2、P3。有两个消费组A和B都订阅了这个主题,消费组A中有4个消费者(C0、C1、C2和C3),消费组B中有2个消费者(C4和C5)。按照Kafka默认的规则,最后的分配结果是消费组A中的每一个消费者分配到1个分区,消费组B中的每一个消费者分配到2个分区,两个消费组之间互不影响。每个消费者只能消费所分配到的分区中的消息。
对于消费者的分区分配而言,Kafka自身提供了三种策略,分别为 RangeAssignor、 RoundRobinAssignor 以及 StickyAssignor ,其中 RangeAssignor 为默认的分区分配策略。
RangeAssignor
RangeAssignor策略的原理是按照消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按照跨度进行平均分配,以保证分区尽可能均匀地分配给所有的消费者。
对于每一个topic,RangeAssignor策略会将消费组内所有订阅这个topic的消费者按照名称的字典序排序,然后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区。
假设n=分区数/消费者数量,m=分区数%消费者数量,那么前m个消费者每个分配n+1个分区,后面的(消费者数量-m)个消费者每个分配n个分区。
为了更加通俗的讲解RangeAssignor策略,我们不妨再举一些示例。假设消费组内有2个消费者C0和C1,都订阅了主题t0和t1,并且每个主题都有4个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t0p3、t1p0、t1p1、t1p2、t1p3。最终的分配结果为:
1 | 消费者C0:t0p0、t0p1、t1p0、t1p1 |
这样分配的很均匀,那么此种分配策略能够一直保持这种良好的特性呢?我们再来看下另外一种情况。假设上面例子中2个主题都只有3个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t1p0、t1p1、t1p2。最终的分配结果为:
1 | 消费者C0:t0p0、t0p1、t1p0、t1p1 |
可以明显的看到这样的分配并不均匀,如果将类似的情形扩大,有可能会出现部分消费者过载的情况。对此我们再来看下另一种RoundRobinAssignor策略的分配效果如何。
RoundRobinAssignor
RoundRobinAssignor策略的原理是将消费组内所有消费者以及消费者所订阅的所有topic的partition按照字典序排序,然后通过轮询方式逐个将分区以此分配给每个消费者。RoundRobinAssignor策略对应的partition.assignment.strategy参数值为:org.apache.kafka.clients.consumer.RoundRobinAssignor。
如果同一个消费组内所有的消费者的订阅信息都是相同的,那么RoundRobinAssignor策略的分区分配会是均匀的。举例,假设消费组中有2个消费者C0和C1,都订阅了主题t0和t1,并且每个主题都有3个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t1p0、t1p1、t1p2。最终的分配结果为:
1 | 消费者C0:t0p0、t0p2、t1p1 |
如果同一个消费组内的消费者所订阅的信息是不相同的,那么在执行分区分配的时候就不是完全的轮询分配,有可能会导致分区分配的不均匀。如果某个消费者没有订阅消费组内的某个topic,那么在分配分区的时候此消费者将分配不到这个topic的任何分区。
举例,假设消费组内有3个消费者C0、C1和C2,它们共订阅了3个主题:t0、t1、t2,这3个主题分别有1、2、3个分区,即整个消费组订阅了t0p0、t1p0、t1p1、t2p0、t2p1、t2p2这6个分区。具体而言,消费者C0订阅的是主题t0,消费者C1订阅的是主题t0和t1,消费者C2订阅的是主题t0、t1和t2,那么最终的分配结果为:
1 | 消费者C0:t0p0 |
可以看到RoundRobinAssignor策略也不是十分完美,这样分配其实并不是最优解,因为完全可以将分区t1p1分配给消费者C1。
StickyAssignor
我们再来看一下StickyAssignor策略,“sticky”这个单词可以翻译为“粘性的”,Kafka从0.11.x版本开始引入这种分配策略,它主要有两个目的:
- 分区的分配要尽可能的均匀;
- 分区的分配尽可能的与上次分配的保持相同。当两者发生冲突时,第一个目标优先于第二个目标。鉴于这两个目标,StickyAssignor策略的具体实现要比RangeAssignor和RoundRobinAssignor这两种分配策略要复杂很多。我们举例来看一下StickyAssignor策略的实际效果。
假设消费组内有3个消费者:C0、C1和C2,它们都订阅了4个主题:t0、t1、t2、t3,并且每个主题有2个分区,也就是说整个消费组订阅了t0p0、t0p1、t1p0、t1p1、t2p0、t2p1、t3p0、t3p1这8个分区。最终的分配结果如下:
1 | 消费者C0:t0p0、t1p1、t3p0 |
这样初看上去似乎与采用RoundRobinAssignor策略所分配的结果相同,但事实是否真的如此呢?再假设此时消费者C1脱离了消费组,那么消费组就会执行再平衡操作,进而消费分区会重新分配。如果采用RoundRobinAssignor策略,那么此时的分配结果如下:
1 | 消费者C0:t0p0、t1p0、t2p0、t3p0 |
如分配结果所示,RoundRobinAssignor策略会按照消费者C0和C2进行重新轮询分配。而如果此时使用的是StickyAssignor策略,那么分配结果为:
1 | 消费者C0:t0p0、t1p1、t3p0、t2p0 |
可以看到分配结果中保留了上一次分配中对于消费者C0和C2的所有分配结果,并将原来消费者C1的“负担”分配给了剩余的两个消费者C0和C2,最终C0和C2的分配还保持了均衡。
如果发生分区重分配,那么对于同一个分区而言有可能之前的消费者和新指派的消费者不是同一个,对于之前消费者进行到一半的处理还要在新指派的消费者中再次复现一遍,这显然很浪费系统资源。StickyAssignor策略如同其名称中的“sticky”一样,让分配策略具备一定的“粘性”,尽可能地让前后两次分配相同,进而减少系统资源的损耗以及其它异常情况的发生。
到目前为止所分析的都是消费者的订阅信息都是相同的情况,我们来看一下订阅信息不同的情况下的处理。
举例,同样消费组内有3个消费者:C0、C1和C2,集群中有3个主题:t0、t1和t2,这3个主题分别有1、2、3个分区,也就是说集群中有t0p0、t1p0、t1p1、t2p0、t2p1、t2p2这6个分区。消费者C0订阅了主题t0,消费者C1订阅了主题t0和t1,消费者C2订阅了主题t0、t1和t2。
如果此时采用RoundRobinAssignor策略,那么最终的分配结果如下所示(和讲述RoundRobinAssignor策略时的一样,这样不妨赘述一下):
1 | 【分配结果集1】 |
如果此时采用的是StickyAssignor策略,那么最终的分配结果为:
1 | 【分配结果集2】 |
可以看到这是一个最优解(消费者C0没有订阅主题t1和t2,所以不能分配主题t1和t2中的任何分区给它,对于消费者C1也可同理推断)。
假如此时消费者C0脱离了消费组,那么RoundRobinAssignor策略的分配结果为:
1 | 消费者C1:t0p0、t1p1 |
可以看到RoundRobinAssignor策略保留了消费者C1和C2中原有的3个分区的分配:t2p0、t2p1和t2p2(针对结果集1)。而如果采用的是StickyAssignor策略,那么分配结果为:
1 | 消费者C1:t1p0、t1p1、t0p0 |
可以看到StickyAssignor策略保留了消费者C1和C2中原有的5个分区的分配:t1p0、t1p1、t2p0、t2p1、t2p2。
从结果上看StickyAssignor策略比另外两者分配策略而言显得更加的优异,这个策略的代码实现也是异常复杂。
自定义分区分配策略
kafka 处理支持默认提供的三种分区分配算法,还支持用户自定义分区分配算法,自定义的分配策略必须要实现org.apache.kafka.clients.consumer.internals.PartitionAssignor接口。PartitionAssignor接口的定义如下:
1 | Subscription subscription(Set<String> topics); |
PartitionAssignor接口中定义了两个内部类:Subscription和Assignment。
Subscription类用来表示消费者的订阅信息,类中有两个属性:topics和userData,分别表示消费者所订阅topic列表和用户自定义信息。PartitionAssignor接口通过subscription()方法来设置消费者自身相关的Subscription信息,注意到此方法中只有一个参数topics,与Subscription类中的topics的相互呼应,但是并没有有关userData的参数体现。为了增强用户对分配结果的控制,可以在subscription()方法内部添加一些影响分配的用户自定义信息赋予userData,比如:权重、ip地址、host或者机架(rack)等等。
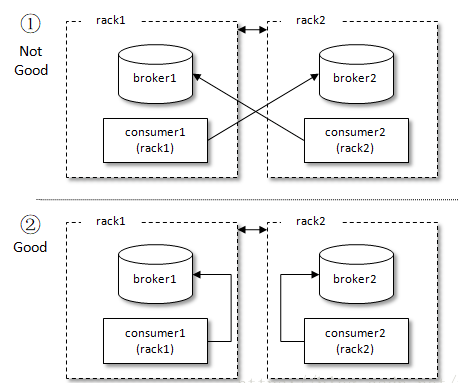
举例,在subscription()这个方法中提供机架信息,标识此消费者所部署的机架位置,在分区分配时可以根据分区的leader副本所在的机架位置来实施具体的分配,这样可以让消费者与所需拉取消息的broker节点处于同一机架。参考下图,消费者consumer1和broker1都部署在机架rack1上,消费者consumer2和broker2都部署在机架rack2上。如果分区的分配不是机架感知的,那么有可能与图(上部分)中的分配结果一样,consumer1消费broker2中的分区,而consumer2消费broker1中的分区;如果分区的分配是机架感知的,那么就会出现图(下部分)的分配结果,consumer1消费broker1中的分区,而consumer2消费broker2中的分区,这样相比于前一种情形而言,既可以减少消费延迟又可以减少跨机架带宽的占用。
再来说一下Assignment类,它是用来表示分配结果信息的,类中也有两个属性:partitions和userData,分别表示所分配到的分区集合和用户自定义的数据。可以通过PartitionAssignor接口中的onAssignment()方法是在每个消费者收到消费组leader分配结果时的回调函数,例如在StickyAssignor策略中就是通过这个方法保存当前的分配方案,以备在下次消费组再平衡(rebalance)时可以提供分配参考依据。
接口中的name()方法用来提供分配策略的名称,对于Kafka提供的3种分配策略而言,RangeAssignor对应的protocol_name为“range”,RoundRobinAssignor对应的protocol_name为“roundrobin”,StickyAssignor对应的protocol_name为“sticky”,所以自定义的分配策略中要注意命名的时候不要与已存在的分配策略发生冲突。这个命名用来标识分配策略的名称,在后面所描述的加入消费组以及选举消费组leader的时候会有涉及。
真正的分区分配方案的实现是在assign()方法中,方法中的参数metadata表示集群的元数据信息,而subscriptions表示消费组内各个消费者成员的订阅信息,最终方法返回各个消费者的分配信息。
Kafka中还提供了一个抽象类org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor,它可以简化PartitionAssignor接口的实现,对assign()方法进行了实现,其中会将Subscription中的userData信息去掉后,在进行分配。Kafka提供的3种分配策略都是继承自这个抽象类。如果开发人员在自定义分区分配策略时需要使用userData信息来控制分区分配的结果,那么就不能直接继承AbstractPartitionAssignor这个抽象类,而需要直接实现PartitionAssignor接口。
下面代码参考Kafka中的RangeAssignor策略来自定义一个随机的分配策略,这里笔者称之为RandomAssignor,具体代码实现如下:
1 | package org.apache.kafka.clients.consumer; |
在使用时,消费者客户端需要添加相应的Properties参数,示例如下:
1 | properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, |
分配的实施
我们了解了Kafka中消费者的分区分配策略之后是否会有这样的疑问:如果消费者客户端中配置了两个分配策略,那么以哪个为准?如果有多个消费者,彼此所配置的分配策略并不完全相同,那么以哪个为准?多个消费者之间的分区分配是需要协同的,那么这个协同的过程又是怎样?
在kafka中有一个组协调器(GroupCoordinator)负责来协调消费组内各个消费者的分区分配,对于每一个消费组而言,在kafka服务端都会有其对应的一个组协调器。具体的协调分区分配的过程如下:
1.首先各个消费者向GroupCoordinator提案各自的分配策略。如下图所示,各个消费者提案的分配策略和订阅信息都包含在JoinGroupRequest请求中。
2.GroupCoordinator收集各个消费者的提案,然后执行以下两个步骤:一、选举消费组的leader;二、选举消费组的分区分配策略。
选举消费组的分区分配策略比较好理解,为什么这里还要选举消费组的leader,因为最终的分区分配策略的实施需要有一个成员来执行,而这个leader消费者正好扮演了这一个角色。在Kafka中把具体的分区分配策略的具体执行权交给了消费者客户端,这样可以提供更高的灵活性。比如需要变更分配策略,那么只需修改消费者客户端就醒来,而不必要修改并重启Kafka服务端。
怎么选举消费组的leader? 这个分两种情况分析:如果消费组内还没有leader,那么第一个加入消费组的消费者即为消费组的leader;如果某一时刻leader消费者由于某些原因退出了消费组,那么就会重新选举一个新的leader,这个重新选举leader的过程又更为“随意”了,相关代码如下:
1 | //scala code. |
解释一下这2行代码:在GroupCoordinator中消费者的信息是以HashMap的形式存储的,其中key为消费者的名称,而value是消费者相关的元数据信息。leaderId表示leader消费者的名称,它的取值为HashMap中的第一个键值对的key,这种选举的方式基本上和随机挑选无异。
总体上来说,消费组的leader选举过程是很随意的。
怎么选举消费组的分配策略?投票决定。每个消费者都可以设置自己的分区分配策略,对于消费组而言需要从各个消费者所呈报上来的各个分配策略中选举一个彼此都“信服”的策略来进行整体上的分区分配。这个分区分配的选举并非由leader消费者来决定,而是根据消费组内的各个消费者投票来决定。这里所说的“根据组内的各个消费者投票来决定”不是指GroupCoordinator还要与各个消费者进行进一步交互来实施,而是根据各个消费者所呈报的分配策略来实施。最终所选举的分配策略基本上可以看做是被各个消费者所支持的最多的策略,具体的选举过程如下:
收集各个消费者所支持的所有分配策略,组成候选集candidates。
每个消费者从候选集candidates中找出第一个自身所支持的策略,为这个策略投上一票。
计算候选集中各个策略的选票数,选票数最多的策略即为当前消费组的分配策略。
如果某个消费者并不支持所选举出的分配策略,那么就会报错。
3.GroupCoordinator发送回执给各个消费者,并交由leader消费者执行具体的分区分配。
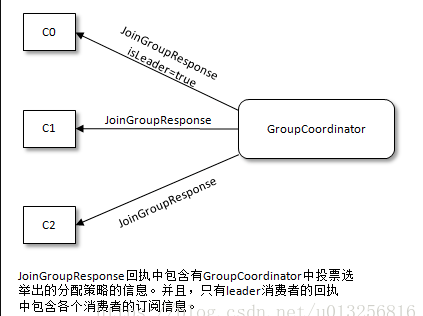
如上图所示,JoinGroupResponse回执中包含有GroupCoordinator中投票选举出的分配策略的信息。并且,只有leader消费者的回执中包含各个消费者的订阅信息,因为只需要leader消费者根据订阅信息来执行具体的分配,其余的消费并不需要。
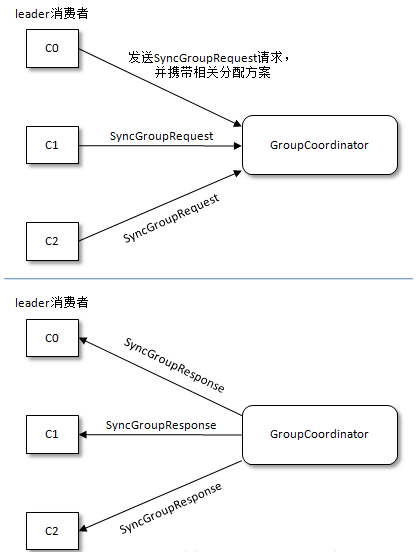
4.leader消费者在整理出具体的分区分配方案后通过SyncGroupRequest请求提交给GroupCoordinator,然后GroupCoordinator为每个消费者挑选出各自的分配结果并通过SyncGroupResponse回执以告知它们。
broker端的分区分配
生产者的分区分配是指为每条消息指定其所要发往的分区,消费者中的分区分配是指为消费者指定其可以消费消息的分区,而这里的分区分配是指为集群制定创建主题时的分区副本分配方案,即在哪个broker中创建哪些分区的副本。分区分配是否均衡会影响到Kafka整体的负载均衡,具体还会牵涉到优先副本等概念。
在创建主题时,如果使用了replica-assignment参数,那么就按照指定的方案来进行分区副本的创建;如果没有使用replica-assignment参数,那么就需要按照内部的逻辑来计算分配方案了。使用kafka-topics.sh脚本创建主题时的内部分配逻辑按照机架信息划分成两种策略:未指定机架信息和指定机架信息。如果集群中所有的broker节点都没有配置broker.rack参数,或者使用disable-rack-aware参数来创建主题,那么采用的就是未指定机架信息的分配策略,否则采用的就是指定机架信息的分配策略。