Docker 系列(三):Docker 核心原理
本文主要介绍了 Docker容器的核心实现原理,包括 Namespace、Cgroups、rootfs 等。
进程就是程序运行起来后的计算机执行环境的总和。
即:计算机内存中的数据、寄存器里的值、堆栈中的指令、被打开的文件,以及各种设备的状态信息的一个集合。
容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。
对于 Docker 等大多数 Linux 容器来说,Cgroups 技术是用来制造约束的主要手段,而 Namespace 技术则是用来修改进程视图的主要方法。
Namespace
Namespace 技术实际上修改了应用进程看待整个计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容。但对于宿主机来说,这些被 “隔离” 来的进程和其他进程没有什么不同。
在 Linux 下可以根据隔离的属性不同分为不同的 Namespace :
- Mount Namespace(CLONE_NEWNS / Linux 2.4.19)
- UTS Namespace(CLONE NEWUTS / Linux 2.6.19)
- IPC Namespace(CLONE NEWIPC / Linux 2.6.19)
- PID Namespace(CLONE NEWPID / Linux 2.6.24)
- Network Namespace(CLONE NEWNET / 始于Linux 2.6.24完成于 Linux 2.6.29)
- User Namespace(CLONE NEWUSER / 始于 Linux 2.6.23 完成于 Linux 3.8)
- Time Namespace
- UTS Namespace
Namespace 存在的问题
首先,既然容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
尽管可以在容器里通过 Mount Namespace 单独挂载其他不同版本的操作系统文件,比如 CentOS 或者 Ubuntu,但这并不能改变共享宿主机内核的事实。这意味着,如果你要在 Windows 宿主机上运行 Linux 容器,或者在低版本的 Linux 宿主机上运行高版本的 Linux 容器,都是行不通的。
而相比之下,拥有硬件虚拟化技术和独立 Guest OS 的虚拟机就要方便得多了。最极端的例子是,Microsoft 的云计算平台 Azure,实际上就是运行在 Windows 服务器集群上的,但这并不妨碍你在它上面创建各种 Linux 虚拟机出来。
其次,在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就 是:时间。
这就意味着,如果你的容器中的程序使用 settimeofday(2) 系统调用修改了时间,整个宿主机的时间都会被随之修改,这显然不符合用户的预期。相比于在虚拟机里面可以随便折腾的自由度,在容器里部署应用的时候,“什么能做,什么不能做”,就是用户必须考虑的一个问题。
下面通过一个案例,来看下 Namespace 的效果:
1 | 使用 python3.6.8 的官方镜像,建立了一个运行 django 的环境 |
可以看到,容器内 PID =1 的进程,是 gunicorn 启动的 django 应用。熟悉 Linux 的同学都知道,PID =1 的进程是系统启动时的第一个进程,也称 init 进程。其他的进程,都是由它管理产生的。而此时,PID=1 确实是 django 进程。
接着,退出容器,在宿主机执行 ps 命令
1 | 环境为 Centos7 |
如果以宿主机的视角,发现 django 进程 PID 变成了 30828. 这也就不难证明,在容器中,确实做了一些处理。把明明是 30828 的进程,变成了容器内的第一号进程,同时在容器还看不到宿主机的其他进程。这也说明容器内的环境确实是被隔离了。
这种处理,其实就是 Linux 的 Namespace 机制。比如,上述将 PID 变成 1 的方法就是通过PID Namespace。在 Linux 中创建线程的方法是 clone, 在其中指定 CLONE_NEWPID 参数,这样新创建的进程,就会看到一个全新的进程空间。而此时这个新的进程,也就变成了 PID=1 的进程。
1 | int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL); |
在 Linux 类似于 PID Namespace 的参数还有很多,比如:
| Namespace | Flag | Page | Isolates |
|---|---|---|---|
| Cgroup | CLONE_NEWCGROUP | cgroup_namespaces | Cgroup root directory |
| IPC | CLONE_NEWIPC | ipc_namespaces | System V IPC,POSIX message queues 隔离进程间通信 |
| Network | CLONE_NEWNET | network_namespaces | Network devices,stacks, ports, etc. 隔离网络资源 |
| Mount | CLONE_NEWNS | mount_namespaces | Mount points 隔离文件系统挂载点 |
| PID | CLONE_NEWPID | pid_namespaces | Process IDs 隔离进程的 ID |
| Time | CLONE_NEWTIME | time_namespaces | Boot and monotonic clocks |
| User | CLONE_NEWUSER | user_namespaces | User and group IDs 隔离用户和用户组的 ID |
| UTS | CLONE_NEWUTS | uts_namespaces | Hostname and NIS domain name 隔离主机名和域名信息 |
Cgroups
通过上面的 Linux Namespace 已经可以创建 “容器” 了,但是会存在
还是以 PID Namespace 为例,来给你解释这个问题。
虽然容器内的第1号进程在“障眼法”的干扰下只能看到容器里的情况,但是宿主机上,它作为第 100 号进程与其他所有进程之间依然是平等的竞争关系。这就意味着,虽然第 100 号进程表面上被隔离了起来,但是它所能够使用到的资源(比如 CPU、内存),却是可以随时被宿主机上的其他进程(或者其他容器)占用的。当然,这个 100号进程自己也可能把所有资源吃光。这些情况,显然都不是一个“沙盒”应该表现出来的合理行为。
而 Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制的一个重要功能。
此外,Cgroups 还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。在本文中,只重点探讨它与容器关系最紧密的“限制”能力,并通过一组实践来带你认识一下 Cgroups。
每一个 CGroup 都是一组被相同的标准和参数限制的进程,不同的 CGroup 之间是有层级关系的,也就是说它们之间可以从父类继承一些用于限制资源使用的标准和参数。
在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。在 Ubuntu 16.04 机器里,我可以用 mount 指令把它们展示出来,这条命令是:
1 | 查看 cgroups 相关文件 |
它的输出结果,是一系列文件系统目录。如果你在自己的机器上没有看到这些目录,那就需要自己去挂载 Cgroups,具体做法可以自行 Google。
在
比如,对 CPU 子系统来说,我们就可以看到如下几个配置文件,这个指令是:
1 | ls /sys/fs/cgroup/cpu |
下面以限制 cpu 为例,展示 Cgroups 是如何进行资源限制的:
首先在 cpu 子系统下面创建一个目录 container,比如,我们现在进入 /sys/fs/cgroup/cpu 目录下:
1 | [root@iz2ze0ephck4d0aztho5r5z cpu]# mkdir container |
container 这个目录就称为一个“控制组”。操作系统会在你新创建的 container 目录下,
现在,我们在后台执行这样一条脚本:
1 | while : ; do : ; done & |
上面的脚本执行了一个死循环,可以把计算机的 CPU 吃到 100%,根据它的输出,我们可以看到这个脚本在后台运行的进程号(PID)是 27218。
查看一下CPU占用
1 | top |
果然这个PID=27218的进程占用了差不多100%的 CPU 资源。
接下来我们就通过 Cgroups 对其进行限制,就用前面创建的 container 这个“控制组”。
我们可以通过查看 container 目录下的文件,看到 container 控制组里的 CPU quota 还没有任何限制(即:-1),CPU period 则是默认的 100 ms(100000 us):
1 | cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us |
文件功能说明(设定CPU使用周期使用时间上限):
- cpu.cfs_period_us:设定周期时间,必须与cfs_quota_us配合使用。
- cpu.cfs_quota_us :设定周期内最多可使用的时间。这里的配置指task对单个cpu的使用上限,若cfs_quota_us是cfs_period_us的两倍,就表示在两个核上完全使用。数值范围为1000 - 1000,000(微秒)。
其他功能说明可参考:https://blog.csdn.net/zhonglinzhang/article/details/64905759
接下来,我们可以通过修改这些文件的内容来设置限制。比如,向 container 组里的 cfs_quota 文件写入 20 ms(20000 us):
1 | echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us |
这样意味着在每 100 ms 的时间里,被该控制组限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程只能使用到 20% 的 CPU 带宽。
接下来,我们把被限制的进程的 PID 写入 container 组里的 tasks 文件,上面的设置就会对该进程生效了:
1 | echo 27218 > /sys/fs/cgroup/cpu/container/tasks |
使用 top 指令查看一下
1 | top |
可以看到,计算机的 CPU 使用率立刻降到了 20% (%Cpu0 : 20.3 us)
除 CPU 子系统外,Cgroups 的每一个子系统都有其独有的资源限制能力,比如:
- blkio,为块设备设定I/O 限制,一般用于磁盘等设备;
- cpuset,为进程分配单独的 CPU 核和对应的内存节点;
- memory,为进程设定内存使用的限制。
Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合。
而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
而至于在这些控制组下面的资源文件里填上什么值,就靠用户执行 docker run 时的参数指定了,比如这样一条命令:
1 | docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash |
在启动这个容器后,我们可以通过查看 Cgroups 文件系统下,CPU 子系统中,“docker”这个控制组里的资源限制文件的内容来确认:
1 | cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us |
5d5c9f67d 其实就是我们运行的一个 Docker 容器,启动这个容器时,Docker 会为这个容器创建一个与容器标识符相同的 CGroup,在当前的主机上 CGroup 就会有以下的层级关系:
1 | cpu --- docker --- 5d5c9f67d |
Cgroups 存在的问题
跟 Namespace 的情况类似,Cgroups 对资源的限制能力也有很多不完善的地方,被提及最多的自然是 /proc 文件系统的问题。
Linux 下的 /proc 目录存储的是记录当前内核运行状态的一系列特殊文件,用户可以通过访问这些文件,查看系统以及当前正在运行的进程的信息,比如 CPU 使用情况、内存占用率等,这些文件也是 top 指令查看系统信息的主要数据来源。
但是,如果在容器里执行 top 指令,会发现,它显示的信息居然是宿主机的 CPU 和内存数据,而不是当前容器的数据。
造成这个问题的原因就是,/proc 文件系统并不知道用户通过 Cgroups 给这个容器做了什么样的资源限制,即:/proc 文件系统不了解 Cgroups 限制的存在。
在生产环境中,这个问题必须进行修正,否则应用程序在容器里读取到的 CPU 核数、可用内存等信息都是宿主机上的数据,这会给应用的运行带来非常大的困惑和风险。这也是在企业中,容器化应用碰到的一个常见问题,也是容器相较于虚拟机另一个不尽如人意的地方。
解决方案: 使用
top 命令是从 /prof/stats 目录下获取数据,所以从道理上来讲,容器不挂载宿主机的 /prof/stats 目录就可以了。
lxcfs 就是来实现这个功能的,做法是把宿主机的 /var/lib/lxcfs/proc/memoinfo 文件挂载到Docker容器的 /proc/meminfo 位置后。容器中进程读取相应文件内容时,LXCFS 的 FUSE 实现会从容器对应的Cgroup中读取正确的内存限制。从而使得应用获得正确的资源约束设定。kubernetes环境下,也能用,以 ds 方式运行 lxcfs ,自动给容器注入争取的 proc 信息。
上面介绍了,Namespace 的作用是“隔离”,它让应用进程只能看到该 Namespace 内的“世界”;而 Cgroups 的作用是“限制”,它给这个“世界”围上了一圈看不 见的墙。这么一折腾,进程就真的被“装”在了一个与世隔绝的房间里,而这些房间就是 PaaS 项目赖以生存的应用“沙盒”。
可是,还有一个问题不知道你有没有仔细思考过:这个房间四周虽然有了墙,但是如果容器进程低头一看地面,又是怎样一副景象呢?换句话说,
以 Dorcker 容器为例:
Docker 镜像是一个只读的 Docker 容器模板,含有启动 Docker 容器所需的文件系统结构及其内容,因此是启动一个 Docker 容器的基础。Docker 镜像的文件内容以及一些运行 Docker 容器的配置文件组成了 Docker 容器的静态文件系统运行环境一rootfs。
可以这么理解,Docker镜像是Docker容器的静态视角,Docker容器是Docker像的运行状态。
rootfs
rootfs 是Docker容器在启动时内部进程可见的文件系统,即Docker容器的根目录。rootfs 通常包含一个操作系统运行所需的文件系统,例如可能包含典型的类Unix操作系统中的目录系统,如/dev, /proc, /bin, /etc, /lib, /usr, /tmp及运行Docke容器所需的配置文件、工具等。
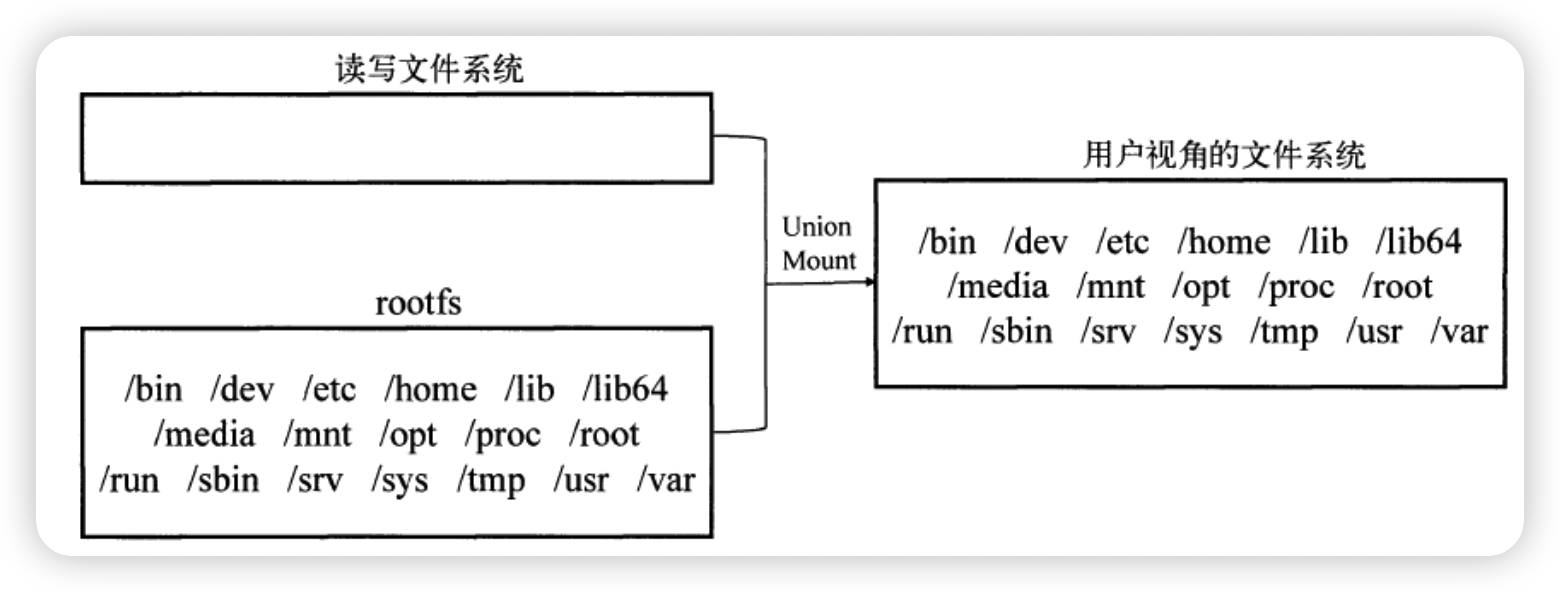
在Docker架构中,当Docker daemon 为Docker容器挂载rootfs时,沿用了Linux内核启动时的方法,即将rootfs设为只读模式。在挂载完毕之后,利用联合挂载(union mount )技术在已有的只读rootfs上再挂载一个读写层。这样,可读写层处于Docker容器文件系统的最顶层,其下可能联合挂载多个只读层,只有在Docker容器运行过程中文件系统发生变化时,才会把变化的文件内容写到可读写层,并隐藏只读层中的老版本文件。
镜像的主要特点
分层
Docker镜像是采用分层的方式构建的,每个镜像都由一系列的“镜像层”组成。分层结构是Docker镜像如此轻量的重要原因,当需要修改容器镜像内的某个文件时,只对处于最上方的读写层进行变动,不覆写下层已有文件系统的内容,已有文件在只读层中的原始版本仍然存在,但会被读写层中的新版文件所隐藏。当使用docker commit提交这个修改过的容器文件系统为一个新的镜像时,保存的内容仅为最上层读写文件系统中被更新过的文件。分层达到了在不同镜像之间共享镜像层的效果。
写时复制
Docker镜像使用了写时复制(copy-on-write)策略,在多个容器之间共享镜像,每个容器在启动的时候并不需要单独复制一份镜像文件,而是将所有镜像层以只读的方式挂载到一个挂载点,再在上面覆盖一个可读写的容器层。在未更改文件内容时,所有容器共享同一份数据,只有在Docker容器运行过程中文件系统发生变化时,才会把变化的文件内容写到可读写层,并隐藏只读层中的老版本文件。写时复制配合分层机制减少了镜像对磁盘空间的占用和容器启动时间。
内容寻址
内容寻址存储( content-addressable storage)的机制,根据文件内容来索引镜像和镜像层。docker对镜像层的内容计算校验和,生成一个内容哈希值,并以此哈希值代替之前的UUID作为镜像层的唯一标志。该机制主要提高了镜像的安全性,并在pull, push, load和save操作后检测数据的完整性。另外,基于内容哈希来索引镜像层,在一定程度上减少了ID的冲突并且增强了镜像层的共享。对于来自不同构建的镜像层,只要拥有相同的内容哈希,也能被不同的镜像共享。
联合挂载
通俗地讲,联合挂载技术可以在一个挂载点同时挂载多个文件系统,将挂载点的原目录与被挂载内容进行整合,使得最终可见的文件系统将会包含整合之后的各层的文件和目录。实现这种联合挂载技术的文件系统通常被称为联合文件系统(union filesystem )。
如下图所示,以运行Ubuntu:14.04镜像后容器中的aufs文件系统为例。由于初始挂载时读写层为空,所以从用户的角度看,该容器的文件系统与底层的rootfs没有差别;然而从内核的角度来看,则是显式区分开来的两个层次。当需要修改镜像内的某个文件时,只对处于最上方的读写层进行了变动,不覆写下层已有文件系统的内容,已有文件在只读层中的原始版本仍然存在,但会被读写层中的新版文件所隐藏,当docker commit这个修改过的容器文件系统为一个新的镜像时,保存的内容仅为最上层读写文件系统中被更新过的文件。
解答灵魂三问
(1). docker 镜像的本质是什么?
答:是一个分层的文件系统。
(2). docker中一个centos镜像大约200M左右,为什么一个centos系统的iso安装文件要好几个G?
答:centos的iso文件包括bootfs和rootfs,而docker的centos镜像复用操作系统的bootfs。
(3). docker中一个tomcat镜像大约500M左右,为什么一个tomcat安装包不足100M呢?
答:docker中的镜像是分层的,tomcat虽然只有70多M,但是它需要依赖父镜像和基础镜像,所有整个对外暴露的tomcat镜像大约500M左右。